On the Opportunities and Risks of Foundation Models - 2021
On the Opportunities and Risks of Foundation Models - 2021
这篇论文是斯坦福大学的一个Center for Research on Foundation Models (CRFM) 机构一百多位科学家联名写的,足足两百多页。
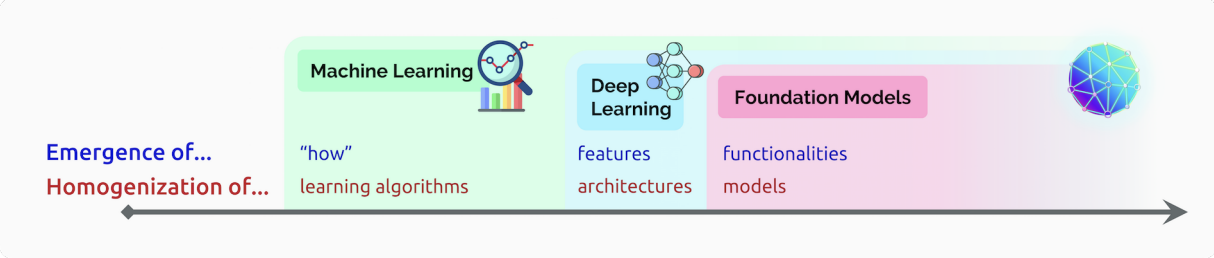
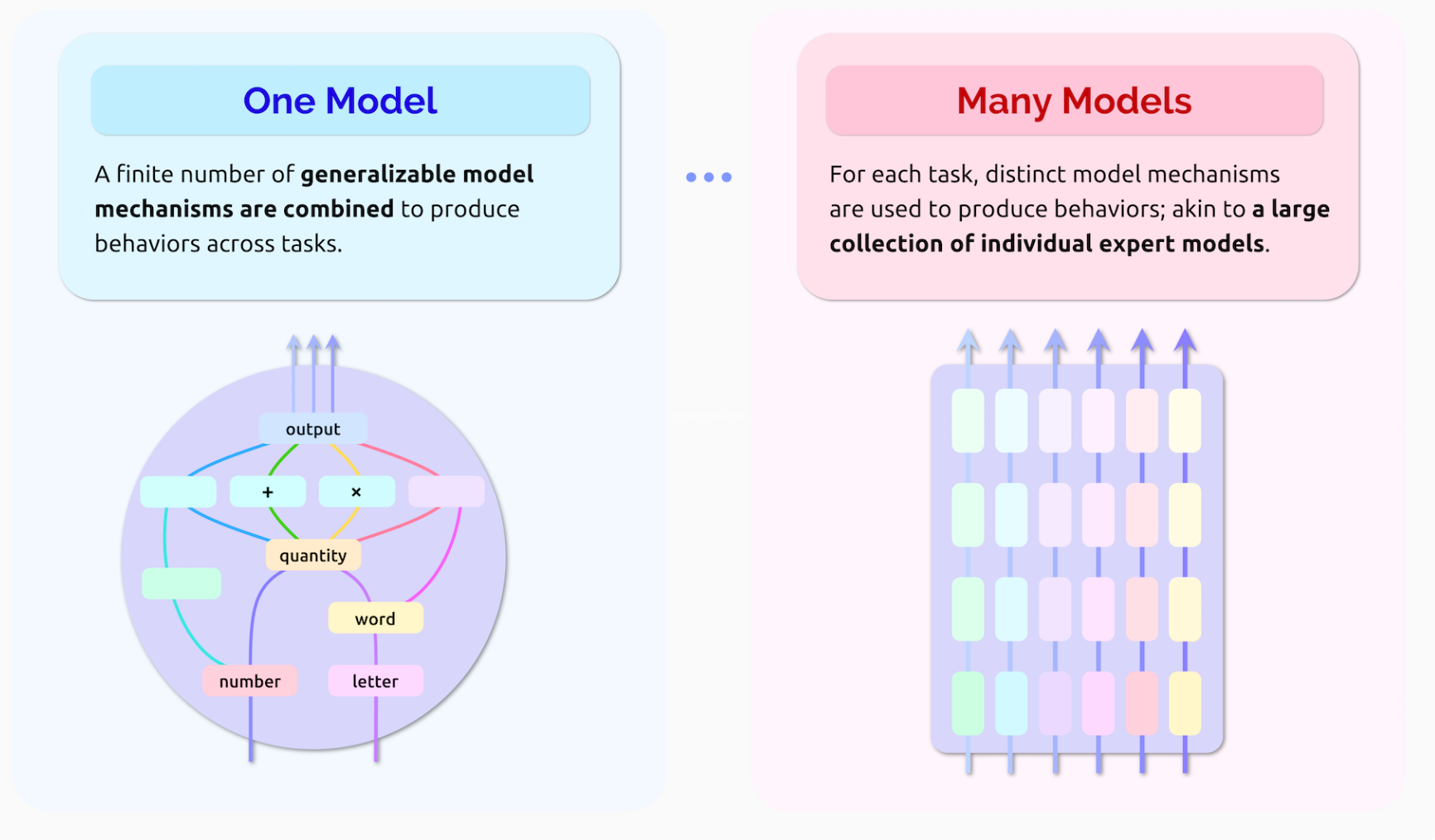
Emergence and homogenization
emergence(涌现),指的是一个系统的功能并不是从外部人为定义的,而是自发地涌现的。比如深度学习的过程中,许多数据集的特征是自发涌现的,而随着越来越多的模型产生,越来越多的特性也随之诞生。
Homogenization(均质化),如上图,指的是从不同层级对AI进行抽象。比如机器学习模型结构本身就是对算法的抽象,而深度学习又将机器学习模型结构抽象为层级和模块,本文提出的Foundation model(基础模型)又是对深度学习模型本身的抽象。
Machine Learning
从90年代起,例如logistic regression之类的通用学习算法,就是迈向均质化的重要一步:许多不同的应用都可以用这类算法。然而一些复杂工作,比如nlp和cv,仍然相当依赖特征工程(feature engineering)来把数据转化成特征,比如SIFT。
Deep Learning
在大约2010年左右,深度学习”死灰复燃“(中间毕竟冷了十几年),得益于半导体的发展,诸如AlexNet这些网络开始在均质化进一步迈进,从不同应用使用不同的特征工程,到同一个网络结构应用于不同程序。
Foundation Models
基础模型的理论是诞生自迁移学习(Thrun 1998)的,它的基本思想就是把一个任务的结果拿出来给其他任务使用。
当然,规模也是极其重要的,需要强大的硬件,Transformer模型(Vaswani 2017)以及海量的数据。
之前的ImageNet数据集是相当经典的,包括之前提到的AlexNet也是在ImageNet benchmark上一举成名。但是这类数据集是依赖标注的,而绝大部分数据都是无标注(unannotated)的。
自监督学习(Self-supervised learning)就是利用无标注数据进行学习的,比如GPT,ELMo,ULMFiT。
之后基于Transformer的自监督学习模型,如BERT,GPT-2,RoBERTa,T5,BART采用了更强大的双向编解码器,并且能够有效地扩展规模。
2019年是一个转折点,19年之前自监督学习只是NLP的一个分支,而现在已经变成了基础。
几乎所有的NLP模型都开始依赖少数的几个基础模型,如BERT,RoBERTa,T5,BART等等。与此同时,它们也会同样遭遇这些模型的bias等缺陷。
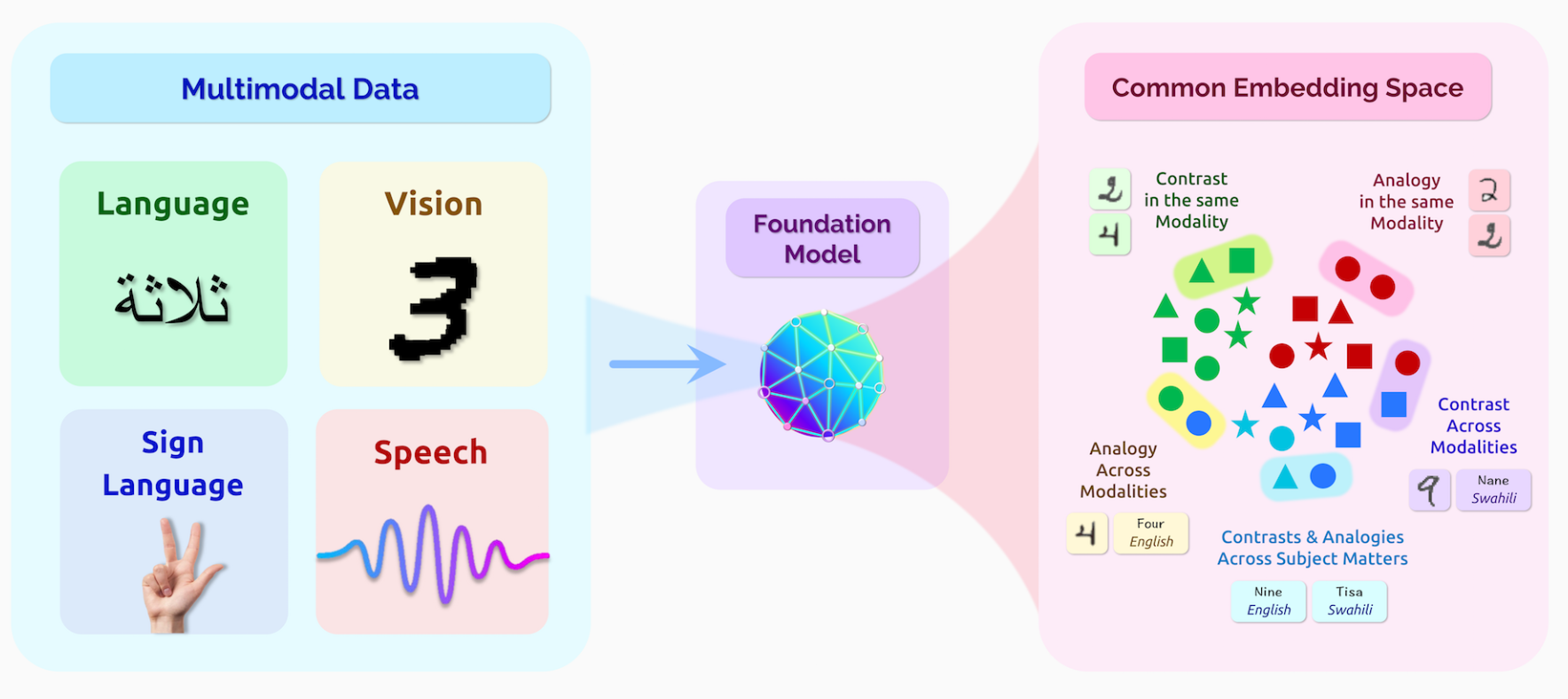
Transformer现在在许多领域都有利用,比如文本、图像、讲话、表格、蛋白质序列、有机分子、增强学习等。
此外,还有一些多模型的基础模型,比如在语言和视觉数据上训练的模型。
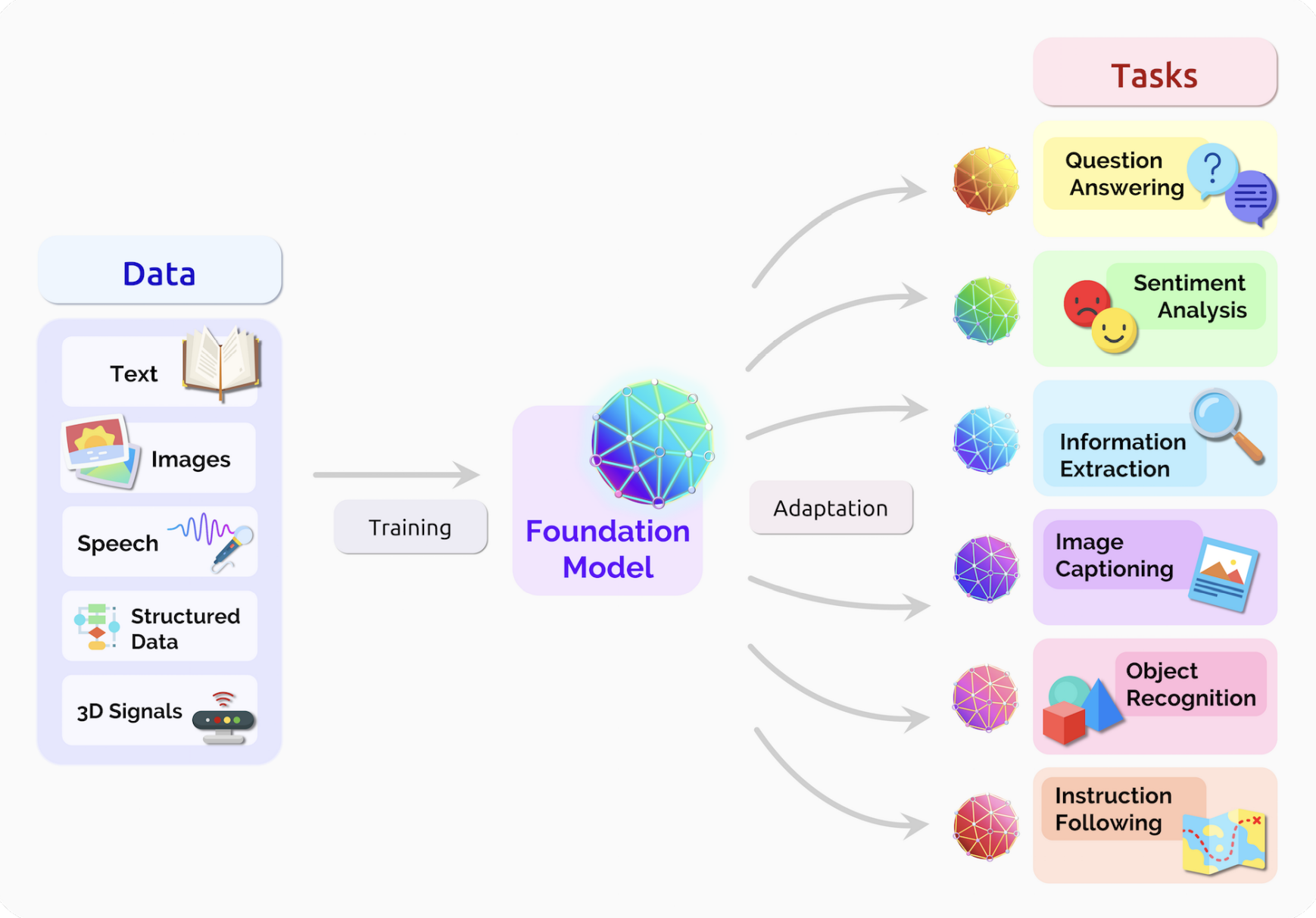
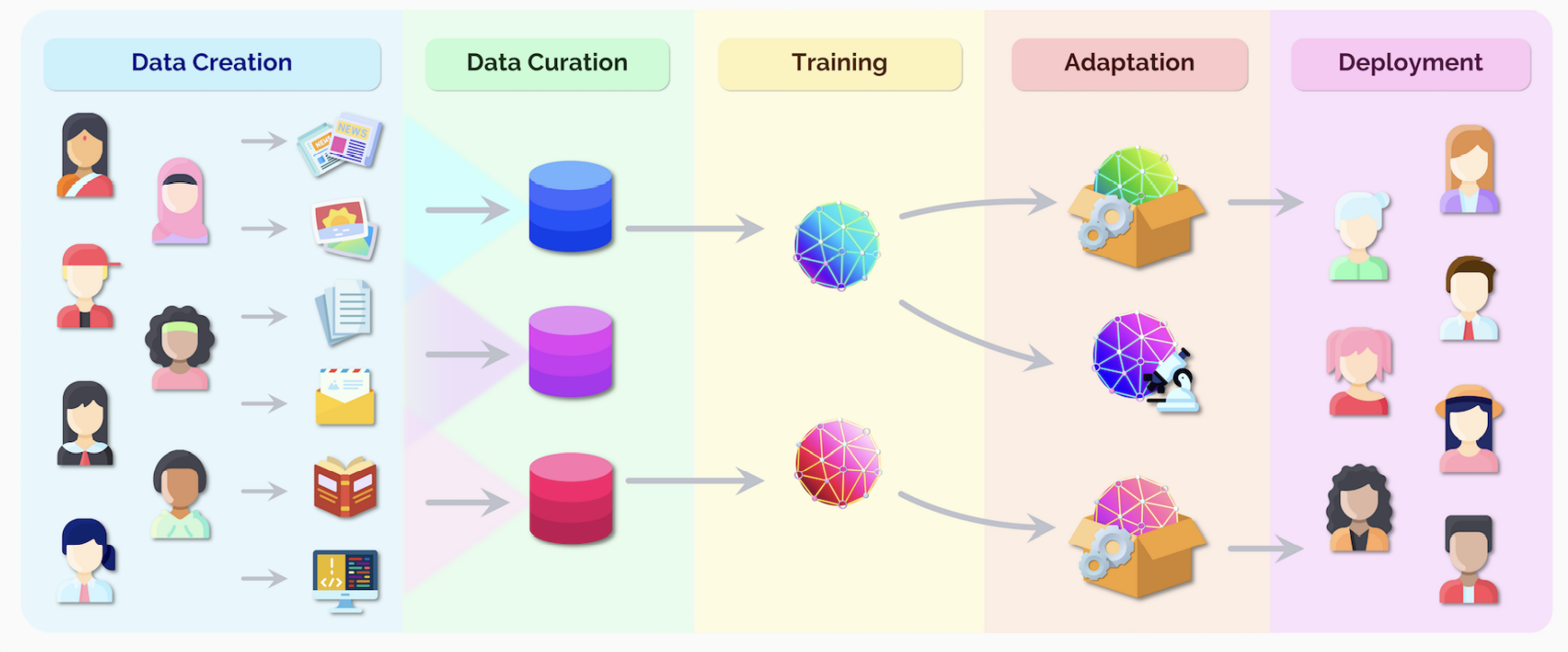
可以看到,我们人类不仅是数据源,也是数据的接受者。因此数据监管也是非常重要的。
Social impact and the foundation models ecosystem
AI系统现在已经迅速在各行各业蓬勃发展,Google现在也采用诸如BERT的基础模型来进行决策。
因此,我们不得不思考AI对社会带来的影响:
- 可能使贫富差距恶化?
- 对经济的影响
- 对环境的影响
- 滥用的后果(disinformation)
- 法律后果
- 伦理争论
Data creation
文中指出,所有数据都是由人类创造的,绝大多数数据都是和人有关的。比如日常交流沟通的数据,对环境的测量(卫星数据),所有数据都是有一定目的的,也是有所有者的。
Data curation
数据整理后成为数据集,包括后处理、数据质量以及合规等环节,是非常重要也非常困难的。
Training
从整理后的数据集进行训练,是许多AI研究的核心,但也只是许多步骤中的一环。
Adaptation
从已有的基础模型创建新的模型,来完成一些工作。例如包含多个不同的模块、特殊的条件、分类器(过滤有害信息)等。
Deployment
当一个AI系统正式部署后,它就已经开始对社会产生影响了。AI系统的部署也应该逐步进行,尽可能减小有可能造成的伤害。
Think ecosystem, act model.
许多AI研究人员、从业人员的权限都仅限于训练阶段。许多基础模型仍然处于未完成的阶段,也并不清楚下游有哪些应用会使用,在什么场景使用。这一点上,需要研究人员对社会、历史有了解。从流程上,文章也提出需要对下游可能的使用场景进行评估,分析。
Disciplinary diversity
学科多样性
每个模型都是从学术、工业的研究诞生的,集合了各个行业的需求和思想。然而,构建这些模型的基本都是大型科技企业,比如Google Facebook Microsoft Huawei
这就使得中心化变成了一个很大的问题,大家都只能在事后分析这些模型对社会的影响和后果,而不是在开发一开始就考量。因此学科重要性是非常重要的,能够很大程度提高社会价值,降低社会危害。
Incentives
市场经济和利润的激励,使得基础模型更加精确、可靠、安全、高效。然而,商业化的激励也可能导致投资不足,投资者不能很好地把握创新的价值。
这里举了医药企业不愿意投入资金研发疟疾药物的例子,因为感染疟疾的通常是生活条件比较差的穷人,而穷人是没有什么钱来买药的。虽然研发出疟疾药物能极大改善这些人的生活,但对药企而言无利可图。
此外,还有对劳动力的替代,信息的健康程度,计算资源对环境的危害,资本的逐利等危害也需要纳入考量。
Loss in accessibility
科研的一个重要要求就是可复现。然而,许多模型如GPT-3都是不开源的,只向少数人提供API接口。甚至训练的数据集都是非开源的。即便训练的模型是开源的,训练的过程也是对绝大多数人不可见的,尤其是一些超大模型,对硬件的超高要求使得其对绝大多数人无法复现。
大公司占有更多、更好的资源,和社区能够做到的模型(如EleuherAI,Hugging Face)的差距只会越来越大。一个解决办法就是政府投资公共基础设施,像哈勃望远镜、LHC等,能够极大地让学术研究受益。
Overview of capabilities
Language
linguistic variation (不同的风格、方言、语言)
language acquisition 语言的习得
Vision
multimodal and embodied data 在多模型、内嵌信息的条件下训练,可以产生更大的进步
Robotics
机器人的一大研究就是开发出通用的机器人,能够执行各种任务。
由于和现实世界深度锚定,机器人领域面临许多挑战。最主要的挑战就是要找到一个新的基础模型,能够获取到足够的数据来学习。这些数据是跨环境、跨模型的。能够让任务和学习更加简单。
Reasoning and search
人类一直以来都是在逻辑上有优势的,因为人可以将知识在不同任务间灵活迁移,能够有更抽象的思考。基础模型对这一领域也提供了许多机会,因为基础模型本身也是面向多任务多目的的。
Interaction
基础模型降低了AI开发、制作原型的门槛,提高了人机交互的天花板。
Philosophy of understanding
基础模型如何理解训练的数据?
Overview of applications
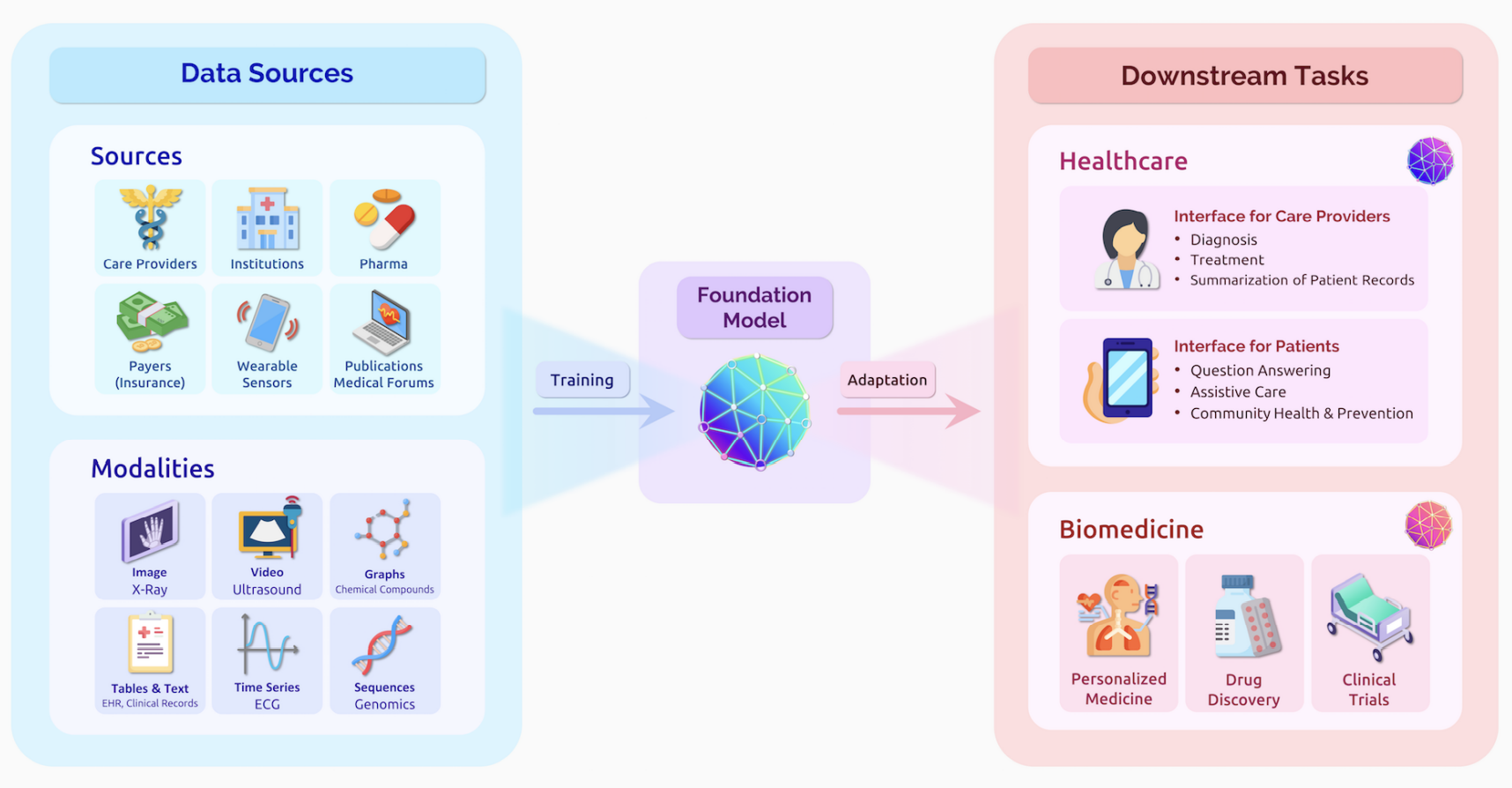
Healthcare and biomedicine
基础模型由于横跨很多模型和领域,提供了许多可能性。如:新药开发,医患交互等。
当然,也存在一定的风险(如使得医药数据的偏见恶化)
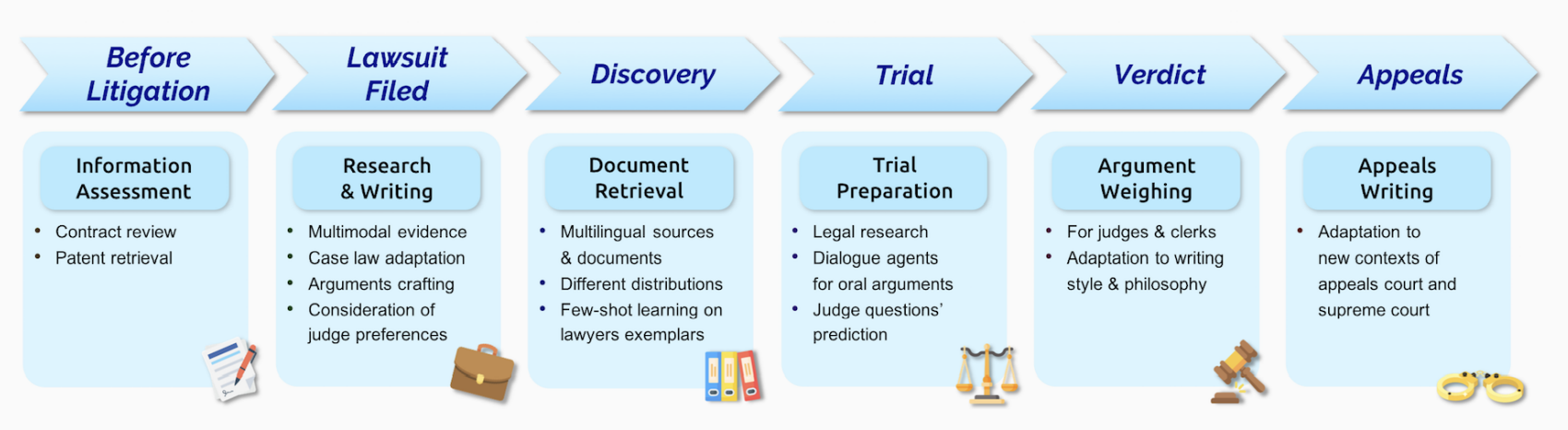
Law
由于拥有海量的数据,包括法律的文件,基础模型可以使得利用不同信息形成判决文件变得可能。
Education
教育是比较微妙,比较复杂的领域,因为要因材施教,而个体的数据又相对而言太少。但是可以换一个角度,由于有不同的数据,如课本、公式、图例、视频等,可以联合起来作为教育任务的可应用辅助。
Overview of technology
Modeling
Expressivity:表达性
如何捕获、同化真实世界的信息,并且能够自由地调整规模。
Multimodallity:多模型
从不同的数据源和领域获取内容,处理内容,然后输出内容
Training
未来的训练目标会反应两个变化:
有原则的选择(根据现实证据和分析)
通用化(丰富、可拓展、统一的训练信号)
Adaptation
如:时间修正,GDPR限制等,从各目标领域出发对模型进行fine-tuning
Evaluation
追踪进度,理解模型,记录它们的能力和bias
Systems
计算机系统是一个数据规模和模型大小的瓶颈。需要同时设计算法、模型、软件和硬件。
Data
训练数据的管理、理解和归档
Security and privacy
安全和隐私当下是基本缺失的。基础模型是单点故障,成为了攻击的目标。(如:adversarial trigger产生不想要的结果),记录训练数据暴露出隐私问题。不正当使用也是一个问题
Robustness to distribution shifts
当下的许多模型都有distribution shift(分布漂移),也就是训练的分布和测试分布不一样。现有的工作现实,广泛地采用无标签数据可以提升模型的健壮性。
AI safety and alignment
确保不被滥用,预测可能出现的行为
Theory
当下,学习是主要基于经验。需要理论的演化。
Interpretability
神经网络的可解释性,透明度
Capabilities
Language
语言是人类思想的中心,也是传达知识、信息的手段。
Natural language processing(NLP), Automatic Speech Recognition(ASR), Text-to-speech(TTS)
想让计算机能够拥有理解、生成人类语言的能力。
基础模型对NLP领域有重大的影响,也是当下大多数NLP系统、研究的中心。
generality and adaptability: 一个单一的基础模型能够在多个用途下完成不同的语言任务。
classification 分类任务:对句子、文档进行分类(如情感分类)
sequence labeling 序列标签任务:对单词、词组进行分类(如预测一个单词是动词还是名词)
span relation classification(关系提取和分析)
generation task(生成新的文本)
过去的NLP任务,经常是会将任务分解为Token segmentation(切分),syntactic parsing(句法分析),coreference resolution(共指消解,指识别表示同一个实体的名词短语或代词,并归类)等。
当今的主要方式是使用一个单一的基础模型,少量地使用标注过得数据来对具体任务进行适配,创建一个适配后的模型。这种模型被证明比之前单独为任务创建的模型更有效。
在2018年之前,生成通用语言被认为是极其复杂的。现在,已经可以训练处高内聚的基础模型。
Bespoke model -> leverage foundation models
语言的多样性:
- 上千种不同的语言、方言
- 不同人不同的习惯
- 书面和口头的不同
- 和朋友 vs 和领导发邮件
全世界6000多种语言,绝大多数都没有足够的资料进行NLP训练。如:西非的Fula有超过6500万使用者,但几乎没有什么训练资源。因此,可以使用多语言的训练模型,如mBERT,mT5, XLM-R都是使用约100种语言训练的。
基础模型和人类语言的一大区别就在于人类的语言是和现实世界息息相关的。婴儿会在学习语言时明白文字的意思,而这一步是通过用手指向物体达到的。
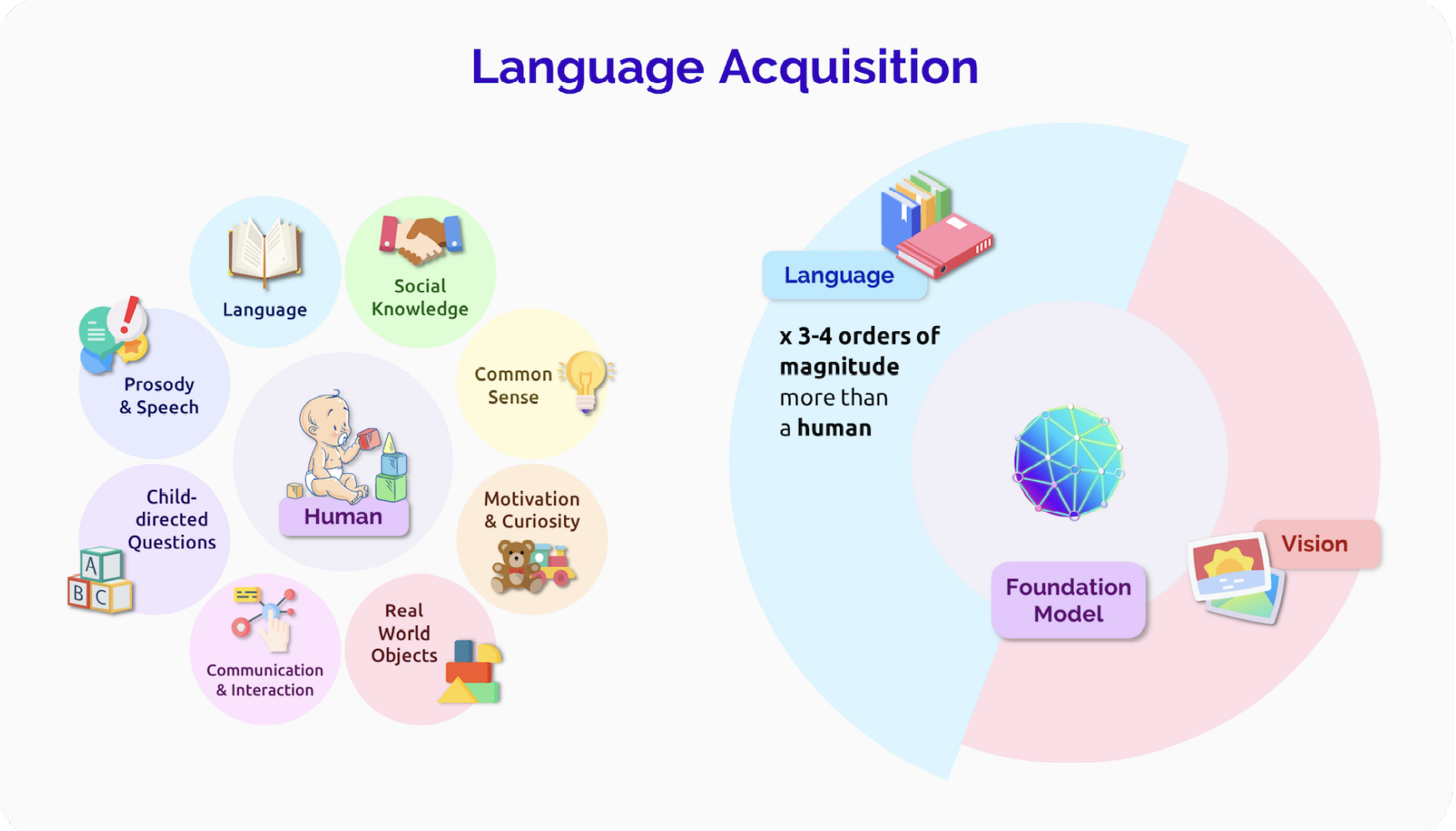
当下,如何不大量训练就能够改变基础的语言模型仍然是未知的。
Vision
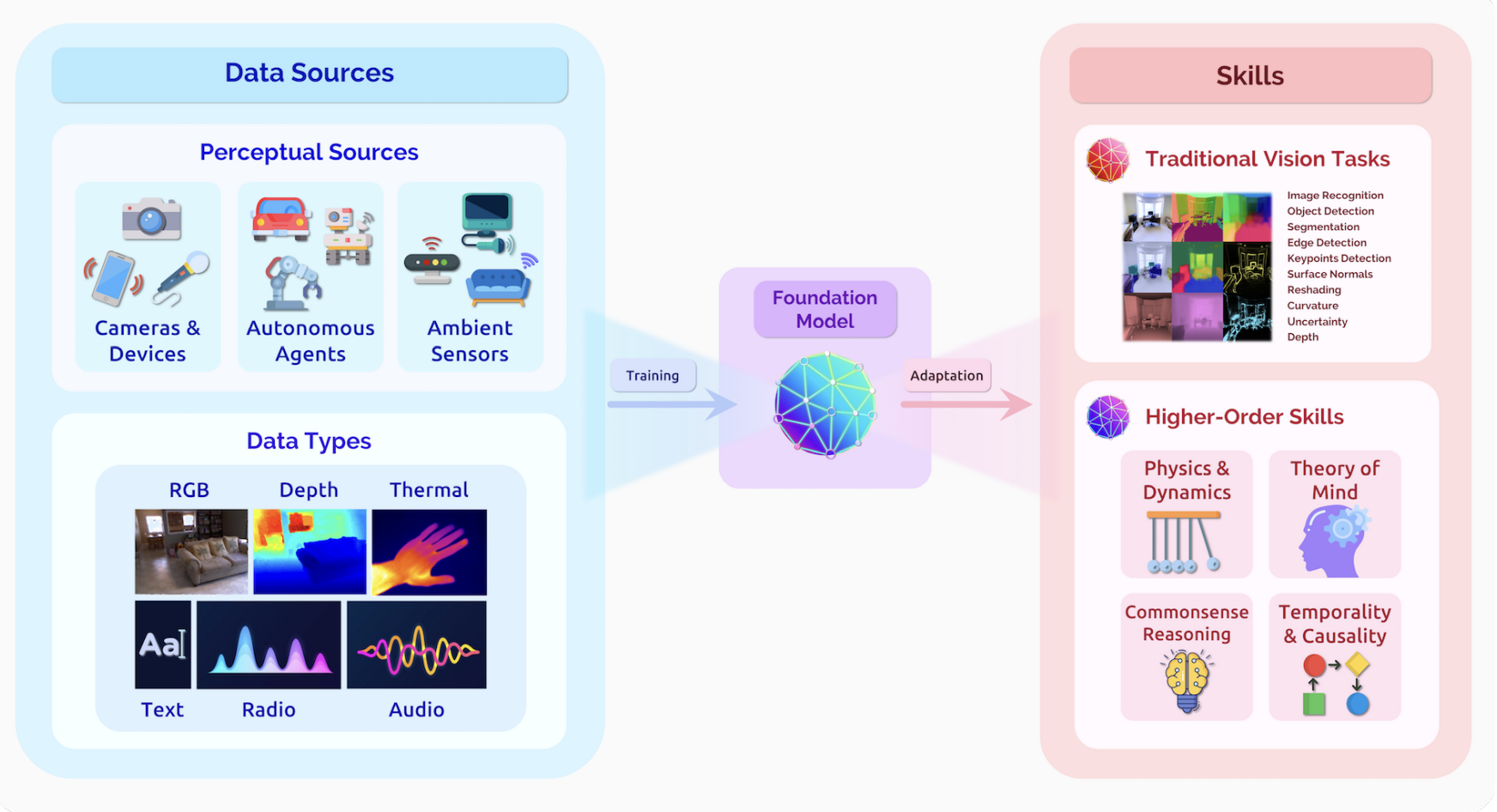
视觉提供了一个接近常量的,长时间的密集信号采集途径。
Hans Moravec in 1988:
In AI, hard problems are easy and likewise easy problems are hard.
ImageNet在2009年的横空出世,标志着有监督训练的计算机视觉的开始。在此基础上,许多模型能够在大量的数据中被训练一次,然后就在各种场景中被应用,比如2012年的AlexNet, 2015年的Inception,2014年的VGG以及 2015年的ResNet。
传统的有监督学习严重依赖严格挑选的标签和标注,限制了模型的鲁棒性、可通用性。近期的一些自监督学习,使用了大量的现实数据来获取对视觉世界的语义化理解。
几个经典的任务:
语义理解任务:如分类、物体检测、语义分割、动作识别、图像生成等
几何、动态和3D任务:静态或动态物体的识别,景深估计,表面检测,曲率与特征点估计。
多模型整合任务:整合语义、几何模型和其他模型如自然语言,如图像标题生成、指令执行等
当前的许多问答系统在回答一些问题时非常艰难,因为许多信息是不包括在图片的像素点中的,需要许多背景知识。比如人类的眼神等。
一些挑战:
ambient intelligence 环境智能 对人类活动敏感并且能作出响应,如医疗应用
mobile and consumer applications 摄影、内容创作等
embodied, interactive agents 对环境变化、物体、动作有捕获
computational efficiency and dynamics modeling
一张1080p的图片就有超过2百万的像素,如果还包含其他的信息,比如语音模型等,计算的开销就非常大。而对数据进行降维,又会影响模型的准确性。
training, environments, and evaluation
输入的质量影响模型的准确性
Robotics
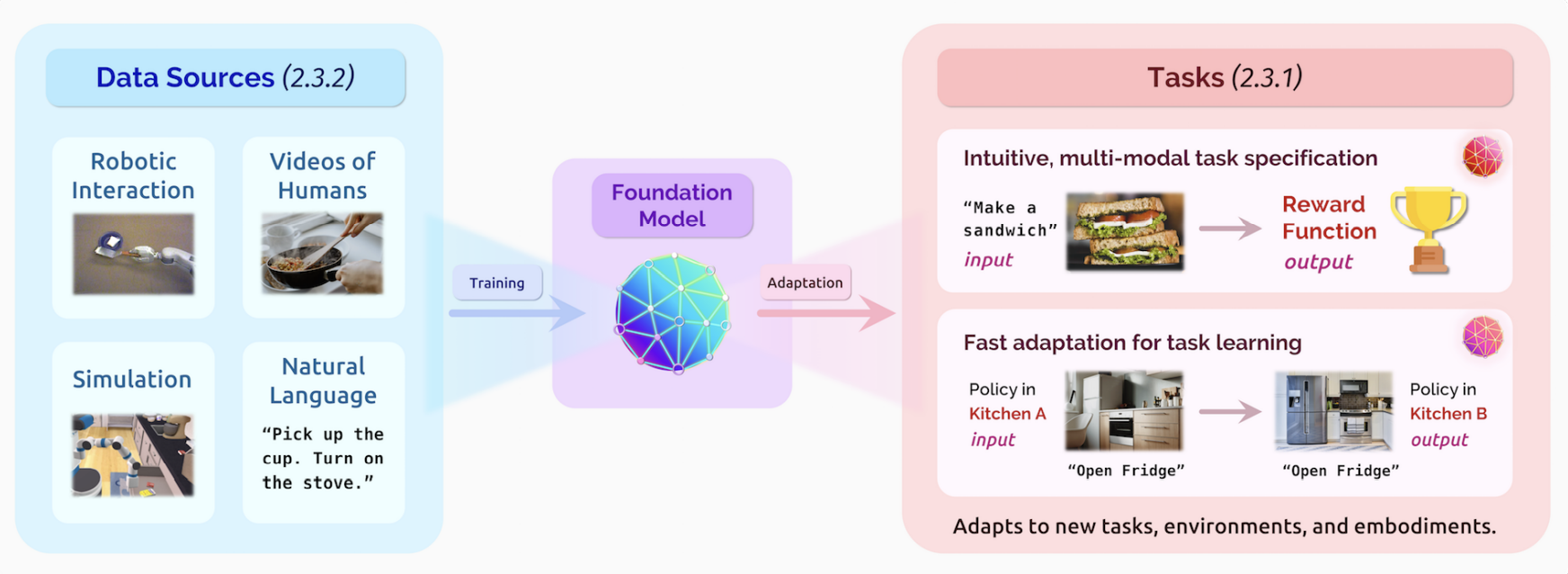
机器人科学的一大挑战就是让机器人能够有能力处理各种各样的情况。
比如,需要一个清单,包含机器人能做的事情,如做饭(在一个新家、新厨房里做饭)。
这就涉及到任务的定义、任务的学习,包含数据的获取和安全、鲁棒性。
然而,现实中,定义这样的任务是很困难的。比如让机器人”做早饭“,早饭在不同人的定义中也不一样。有些人的早饭是面包、煎蛋加果汁,有些人是咖啡配烤肉,有些人则是煎饼油条配豆浆。我们发现,这些任务都是context-dependent(情景依赖)的。
和NLP的"text-in, text-out"不同,许多机器人的任务是有多种多样的输入和输出的。
让机器人做事情,在让它们知道”怎么做“之前,先得知道”做什么“。这就需要对任务的定义有很强的能力,牵扯到有效的沟通,生成偏好、限制等。这些又牵扯到人机之间的有效交互,人类需要给机器人进行评价(feedback),来帮助机器人学习、提升完成任务的能力。
除此之外,能够将任务的定义迁移到新环境、新任务也是非常重要的能力。这在目前还是一个问题。
数据的采集,也是一个问题。
安全和鲁棒性,也是机器人特有的问题。
Reasoning and search
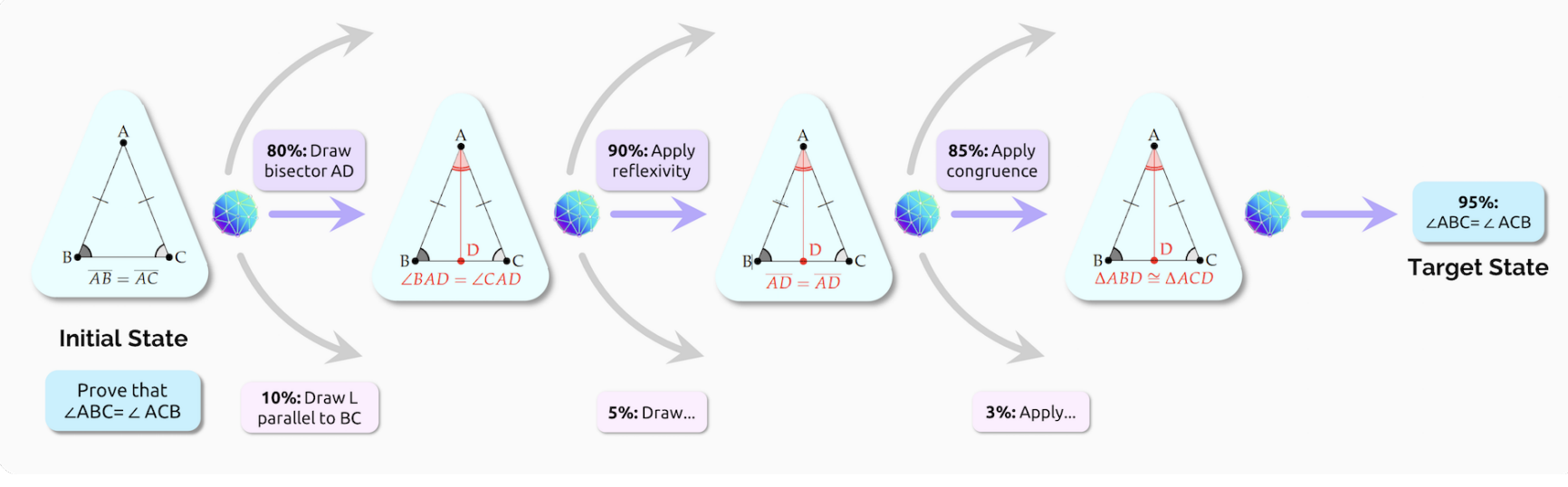
例如要证明等腰三角形的∠B = ∠C,系统可以在任意时刻采取任意数量的行动。如果把增加辅助线算上,那么系统也可以进行任意的构造,比如垂线、平行线、内切圆等,只会增加搜索的空间。
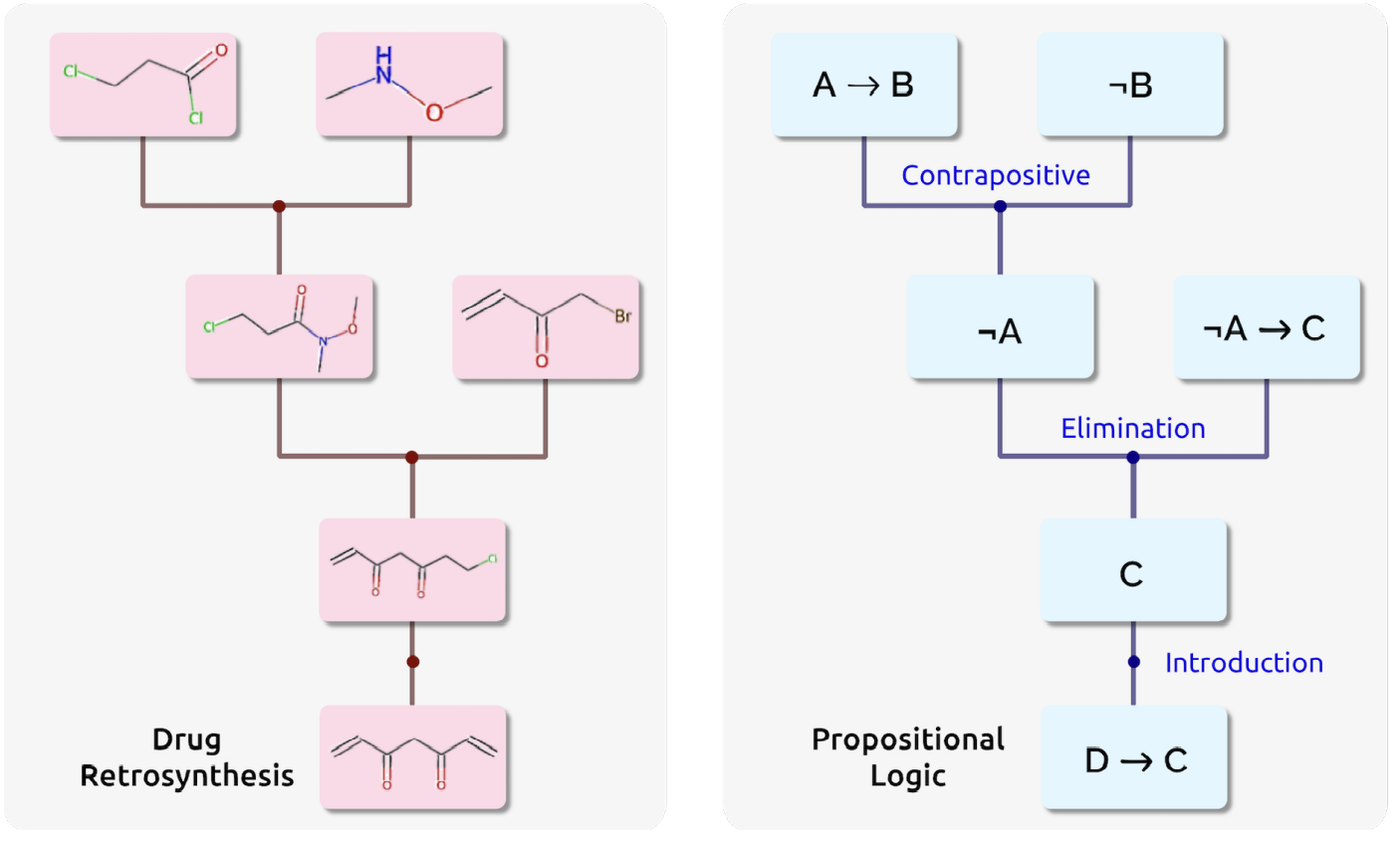
数学家可以使用各种领域的知识,找到对应的例子。
许多问题是具有unbounded search space的,比如制作程序、药物发现、化学合成、设计、组合优化等。
与此同时,高质量的标注数据十分稀缺。
Interaction
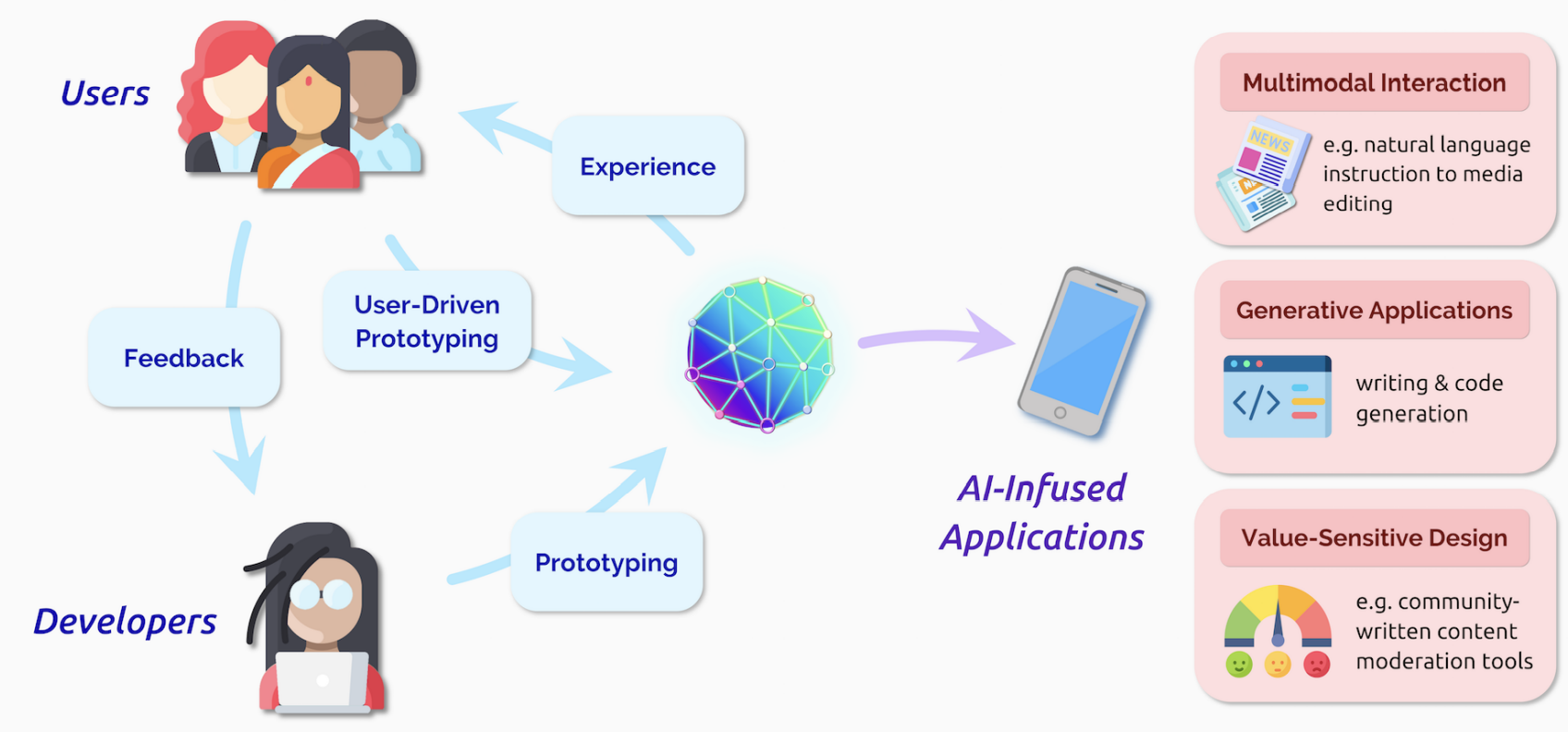
GPT-3,DALL-E等应用向人们展示了非ML专家也能使用AI驱动强大的应用。
降低了开发成本,提高了上限,但也是一把双刃剑:模型变得越来越复杂的同时,也会越来越难以控制和预计。
开发者和终端用户的界线正在变得模糊。
Philosophy of understanding
对各种基础模型,很难对它们下一个通用的定义。但它们都有一个共同的特点:自监督学习。
了解”三明治包含花生“这个短语后面很可能跟着”酱“并不能让模型知道三明治是什么,花生酱是什么,为什么它们要组合在一起等等。我们不能让模型仅仅局限于文字的输入。
信任、可靠性也是一个潜在的风险。
Applications
Healthcare and biomedicine
医疗相关的开支已经占了美国GDP的17%。
机会和前景:
药物开发是相当复杂的过程,从基本的药物研究(蛋白质靶向识别),潜在的分子发现,医学试验到最终的药物审批,基本需要超过10年的过程,消耗超过十亿美元。医药急需一种能够利用现有的发现的数据加速医药探索。
2021年Lu 等人发现Transformer也可以用于蛋白质折叠预测。
药物发现、个性化医疗、临床试验等,都可以从基础模型得到改善。
Extrapolation 外推
从已有的数据集外推到新的数据是一项机器学习挑战。诸如GPT-3等能够生成未发现的新序列,但还是出于萌芽阶段。
Law
根据2021年的统计,美国有超过130万律师,每年的法律事务营收超过3000亿美元。因此,法律服务变得很昂贵,大多数人都承担不起。根据Legal Services Corporation 2017年的调查,86%的低收入人群认为没有得到或者只得到了极少的法律帮助。
基础模型可以降低法律的门槛,提高普通人采取法律为自身维权的程度。
比如,还可以对法院的审判转成文字来找出异常情况。
平均美国最高法院的opinion包含大约4700个词,案情简介可能高达15000词,法律评论文章包含20000~30000词,而假释笔录则会几百页长,审判记录甚至更长。现有的基础模型面对如此长的文章和输出还是非常挣扎的。

除了理解文件,基础模型还需要理解哪些案例中法律是有效的,哪些是不能采用相关法律的,需要一定的概念迁移能力。法律判决还需要有能力识别相关的条例,以及这些条例如何应用在新的场景。这又需要一定的逻辑推断能力。显然,目前的BERT模型还不具备相关的能力(即便预先使用法律文书训练)
现有的如GPT-3等模型甚至不能完成很简单的逻辑推理。
而对于法律而言,准确性又恰恰是非常重要的。与此同时,训练也没有大量的数据集,许多案件都是特例,因此需要有从少数特例中学习的能力。训练的结果还需要有适应能力,并且是可靠的。
Education
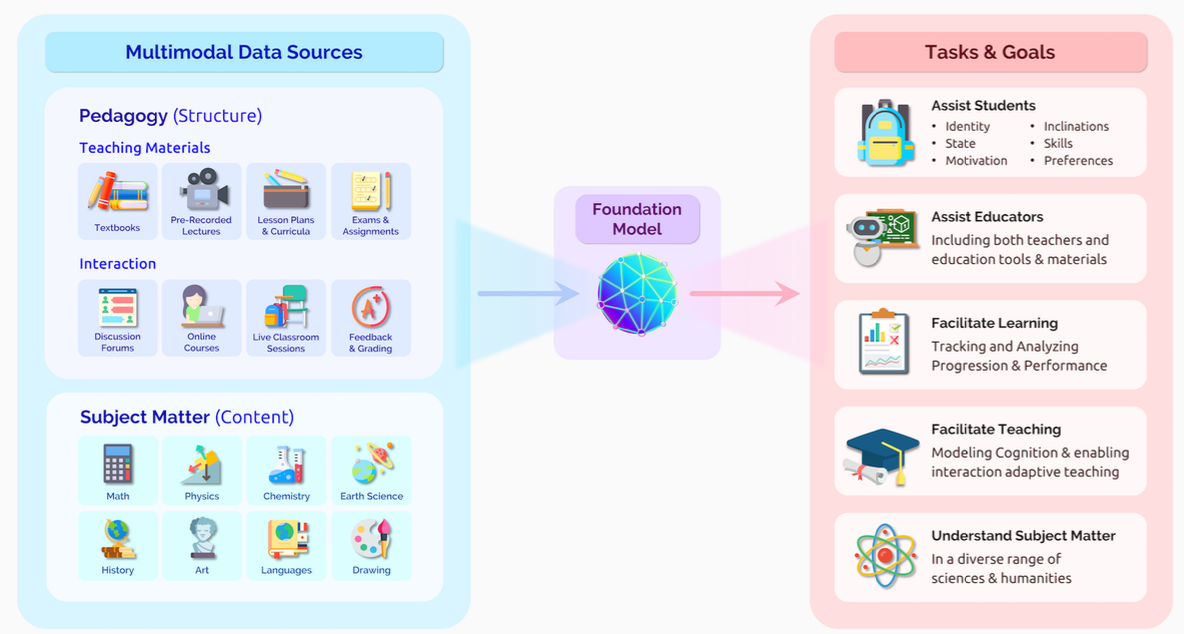
在2000年,世界各国的首脑都聚集在联合国千年峰会上,代表们总结得出教育应当是首要的目标。
一个主要的目标,就是提升生产率,单位时间学到的东西更多。这可能导致老师失业。
然而,使用AI辅助教学也使得老师更难了解学生的学习情况。
Github CoPilot:代码生成AI,基于GPT-3
要让AI能够了解学生的学习情况,需要两个核心的能力:
1、了解任务的主要内容
2、有诊断的能力,以及提醒的能力,并且能够推断为什么学生犯了错。
然而比较麻烦的是,现在的教室中的互动并不能给AI提供足够多的学习数据。
同时,还需要对教育学有了解,知道怎么引导学生,比如问一些问题,提供例子/反例等,使用鼓励性的话语,问适合学生难度的问题,并且生成和学生的兴趣、背景相关的例子等。
Technology
Modeling
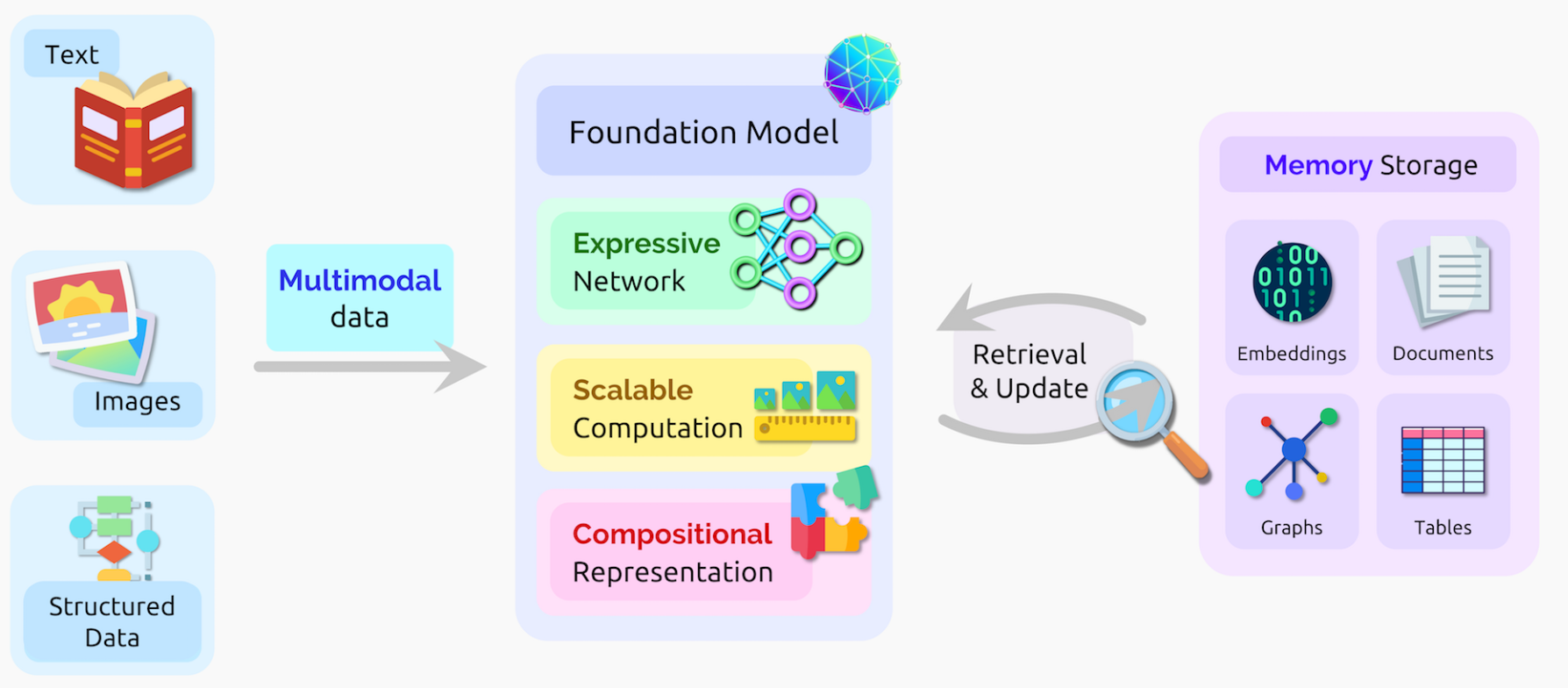
基础模型的五个关键属性:
expressivity — 能够灵活地捕捉、表达丰富的信息
scalability — 高效地处理海量的数据
multimodality — 连接各种不同的模型和领域
memory capacity —存储大量积累的知识
compositionality — 生成新的场景、任务和环境
Expressivity
网络模型的理论、实际对数据分布的表达能力,以及灵活性。没有一个模型能够完美地适配所有场景。
Inductive Biases
归纳偏置
归纳偏置,让算法优先某种解决方案,这种偏好是独立于观测的数据的。
常见的归纳偏置,包括:贝叶斯算法中的先验分布、使用某些正则项来惩罚模型、设计某种特殊的网络结构等。
好的归纳偏置,会提升算法搜索解的效率(同时不会怎么降低性能),而不好的归纳偏置则会让算法陷入次优解,因为它对算法带来了太强的限制。
归纳偏置,一般是对样本的产生过程,或者最终解的空间的一些假设。例如我们设计各种模型结构/形式,就是对解的空间上的假设。
可以看到,全连接网络的inductive bias是最轻微的,它就是假设所有的单元都可能会有联系;卷积则是假设数据的特征具有局部性和平移不变性,循环神经网络则是假设数据具有序列相关性和时序不变性,而图神经网络则是假设节点的特征的聚合方式是一致的。总之,网络的结构本身就包含了设计者的假设和偏好,这就是归纳偏置。
Transformer Networks & Attention.
捕获长程依赖,高层级的元素交互。
自注意力机制:提供一种方式,来对比横跨输入数据的元素。
General-Purpose Computation.
注意力提供的更好的泛化能力,不再是和任务/业务强耦合。
任务的专业性和模型的表达性之间是需要有权衡的。
减小归纳偏置,让数据为自己代言
Challenges & Future Directions
效率和表达性之间的权衡
语言、逻辑方面的研究
Optimization
基础模型应当能够容易训练,容易使用
Hardware Compatibility
高效,能够并行化处理
Generality and Specialization
模型的结构共享(structural sharing)
AI的能力需要泛化来提升
Multimodal Interactions
weight sharing 共享权重
early-fusion 模型,cross-modal(late-fusion)模型
Explicit Storage
explicit fact 存储在外部存储中
implicit knowledge 存储在网络的可训练权重中
存储和计算的分离
Key-value 结构存储
Information Retrieval
外部提示、内部重构
知识图谱
存储能力和表现力的权衡
Knowledge Manipulation
事实的准确性和合法性会随着时间改变,因为世界是在不断变化的。
模型也因此需要某种机制来及时、高效地更新数据,不断学习。
Compositionality
out-of-distribution, combinatorial generalization(组合泛化)
Model
interpretability 可解释性
multimodality 多模型
Computation
对子网络进行特化的权重更新
iterative computation
Training & Data
ensemble techniques 集成学习
Representation
multi-hop reasoning 多步推理
Training
Leveraging broad data
自监督学习引发了对大规模数据集的需求,包括图像、音频、视频、传感器数据、文字等等。
Domain completeness
解决训练任务所需的能力是对下游的应用有用的。但目前到底什么任务呢能够获取领域完整性,还是不确定的。
Scaling and compute efficiency
随着自监督学习的不断发展,计算资源逐渐成为了瓶颈。
At what level of abstraction should we model?
如果是byte level的模型,那么会导致模型更多地关注非语义的信息,导致学习的速率变慢。transformer模型更加加重了这一点,因为随着输入的增加,计算的成本是o(n^2^)增加的。
如果使用领域相关的知识来减小输入的空间,那么可能会丢失一些有用的信息。这是需要权衡的。
Generative vs discriminative models
生成式模型(generative)
优点:
由于统计了数据的分布情况,所以其实际带的信息要比判别模型丰富,对于研究单类问题来说也比判别模型灵活性强; 模型可以通过增量学习得到(增量学习是指一个学习系统能不断地从新样本中学习新的知识,并能保存大部分以前已经学习到的知识。); 收敛速度更快,当样本容量增加的时,生成模型可以更快的收敛于真实模型; 隐变量存在时,也可以使用。
缺点
- 学习和计算过程比较复杂,由于学习了更多的样本信息,所以计算量大,如果我们只是做分类,就浪费了这部分的计算量;
- 准确率较差
判别式模型(discriminative)
优点
- 由于关注的是数据的边界,所以能清晰的分辨出多类或某一类与其他类之间的差异,所以准确率相对较高;
- 计算量较小,需要的样本数量也较小;
- 往往需要对特征进行假设,比如朴素贝叶斯中需要假设特征间独立同分布,所以如果所选特征不满足这个条件,将极大影响生成式模型的性能。
缺点
- 不能反映训练数据本身的特性;
- 收敛速度较慢。
- 不能处理隐变量
无监督学习可以看成是 GM 的一种
Adaptation
比如,在文本概括任务中,增加TL;DR前缀能够提升基础模型的性能。
优化的主要三个要素:
Compute budget
许多减小模型存储压力的方式,如:只调整最后一层,或者只调整偏置向量。
这些任务看上去向性能妥协了,但是和full fine-tuning相比表现并不差。
Data availability
标注MRI数据需要医学专家的经验,标注文字情感只需要常识。在训练资源有限时,包含提示和精调的方式是更好的。
Access to foundation model gradients
由于内存的限制,许多基础模型的参数对大多数组织和机构都是没有能力去调整的。如GPT-3等模型更是直接只提供API。
适配用例
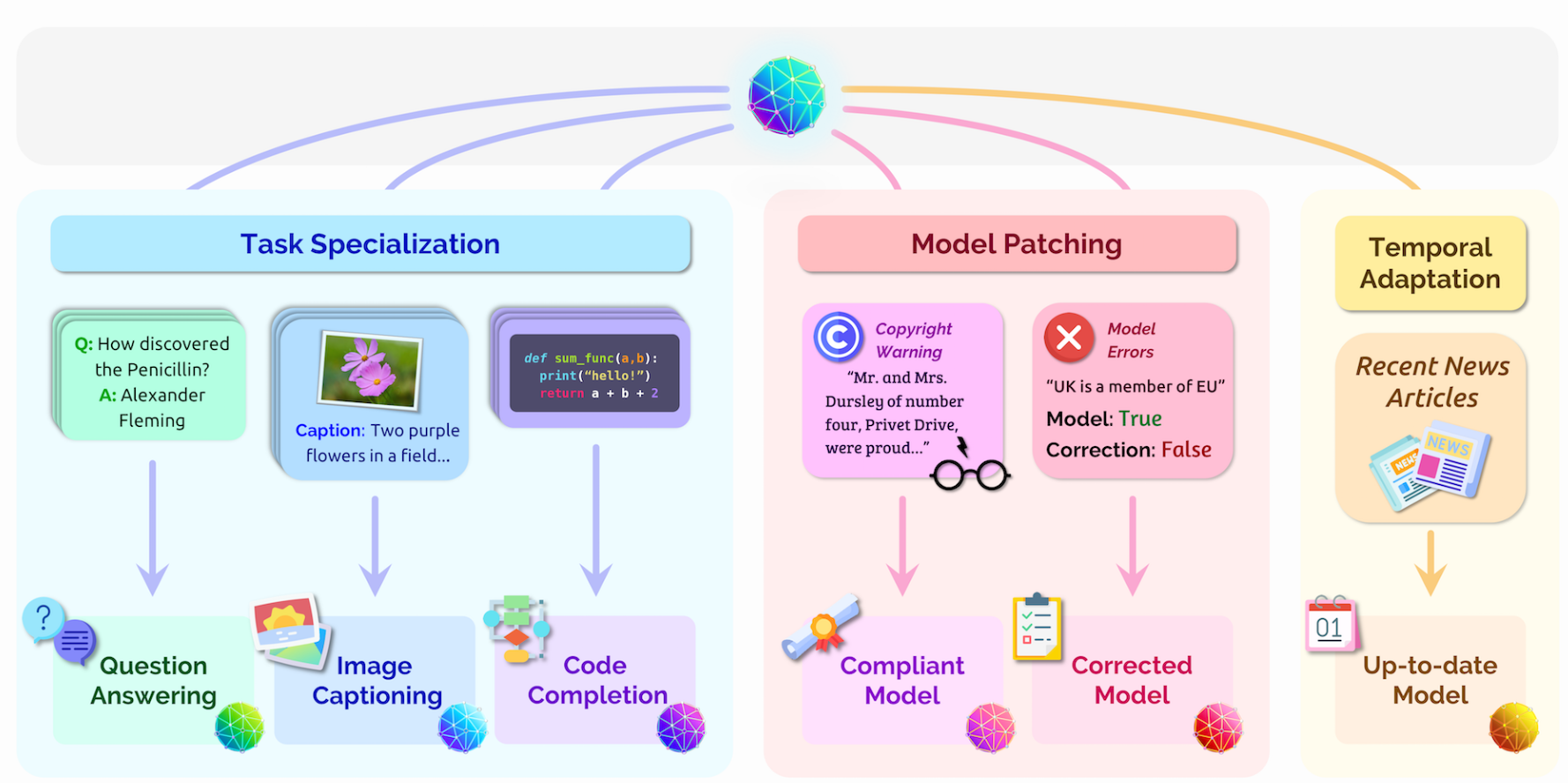
Task specialization
最广泛使用
Temporal adaptation
Temporal shift:时间迁移问题
由于训练基础模型所需的计算资源极其巨大,随着时间不断更新变得很困难。
语言模型:时间分隔的训练集
Domain specialization
LegalBERT vs BERT
Local model editing
如果希望对某个、某些输入得到的结果进行修正,那么我们只希望模型对这些输入的输出有变化,而对其他的输出没什么变化。现有的方法在稳定性上都有些问题,很难做到修改模型的同时不影响全局的表现。
Applying constraints
隐私限制
Evaluation
我们如何测量模型的性能,如何设计更好的模型?
我们如何理解模型的行为,模型在不同的数据上表现如何
如何总结模型的行为,向大众解释
intrinsic 对基础模型的评估,和任务无关
Extrinsic 对具体任务模型的评估,除了基础模型还有适配
现有的一些评估,如:分析模型对下一个单词的预测对不对,难以达到泛化的效果。而且,随着模型越来越复杂,这种评估也变得很困难了。比如要评估模型生成的内容是否优秀,这些就非常困难了。
Imputing intrinsic evaluation from broad extrinsic evaluation
有一种方式就是干脆让模型去执行各种各样的任务,然后测量整体的表现。比如meta-benchmarks
Direct evaluation of intrinsic properties
许多人类相关的研究也可以用于模型的研究,因为模型的许多任务都和人类似。
Systems
Data
在更大的尺度上管理数据
将数据集成到新的模型中
监管、牌照
数据质量
Scalability
公共数据和个人、企业数据相比只是很小一部分,因此需要有一种处理大规模数据集的方式。
Data integration
整合结构化和非结构化的数据,能够让模型在冷门的概念上更好地泛化。
如何整合各种各样的数据,能够达到工业化使用的标准
Privacy and governance controls
爬虫数据
使用网络数据是否合法
Understanding data quality
如何系统化地判断数据的质量还在早期阶段。
Open questions
数据的版本更新,老版本还可以使用?
保护个人的隐私 vs 溯源
数据中心可能是由NGO、社区、个人运行的,谁为数据负责?
动态更新、淘汰机制
Security and privacy
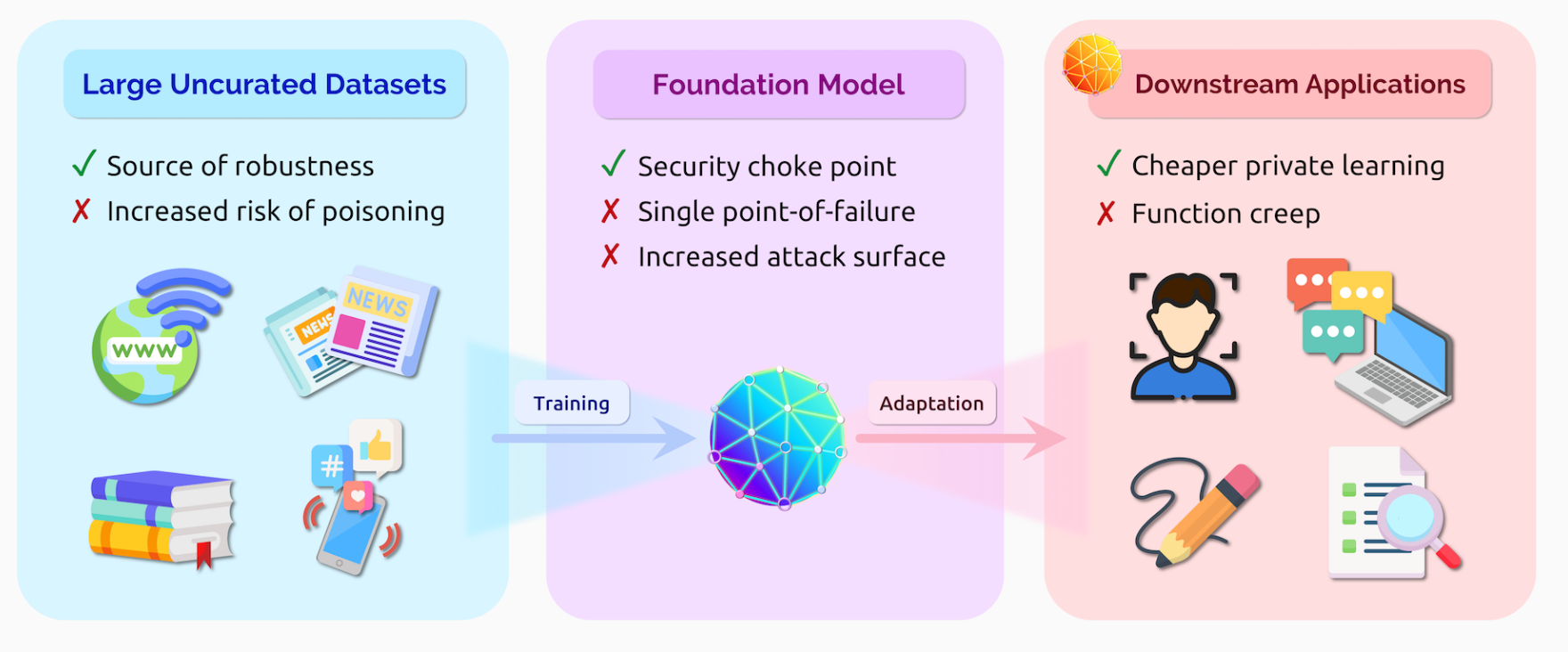
Single points of failure
基础模型对应用而言是一个单点故障,一旦遭受数据攻击(data poisoning attack),可能会影响所有使用该模型的应用。
许多模型现在直接使用网络上未处理的信息,加剧了数据攻击的可能性。
Function creep & dual use
CLIP最初只是用于解决图片-文字的匹配,但最终却学习了许多脸部特征。
Multimodal inconsistencies
CLIP将苹果分类为iPod
许多模型依赖其他模型
Robustness to distribution shifts
CLIP和ResNet50都在ImageNet上有大约76%的准确率,但是在ImageNetV2上CLIP表现更好,超过了ResNet50 6%,而在ImageNet Sketch上更是超出了35%
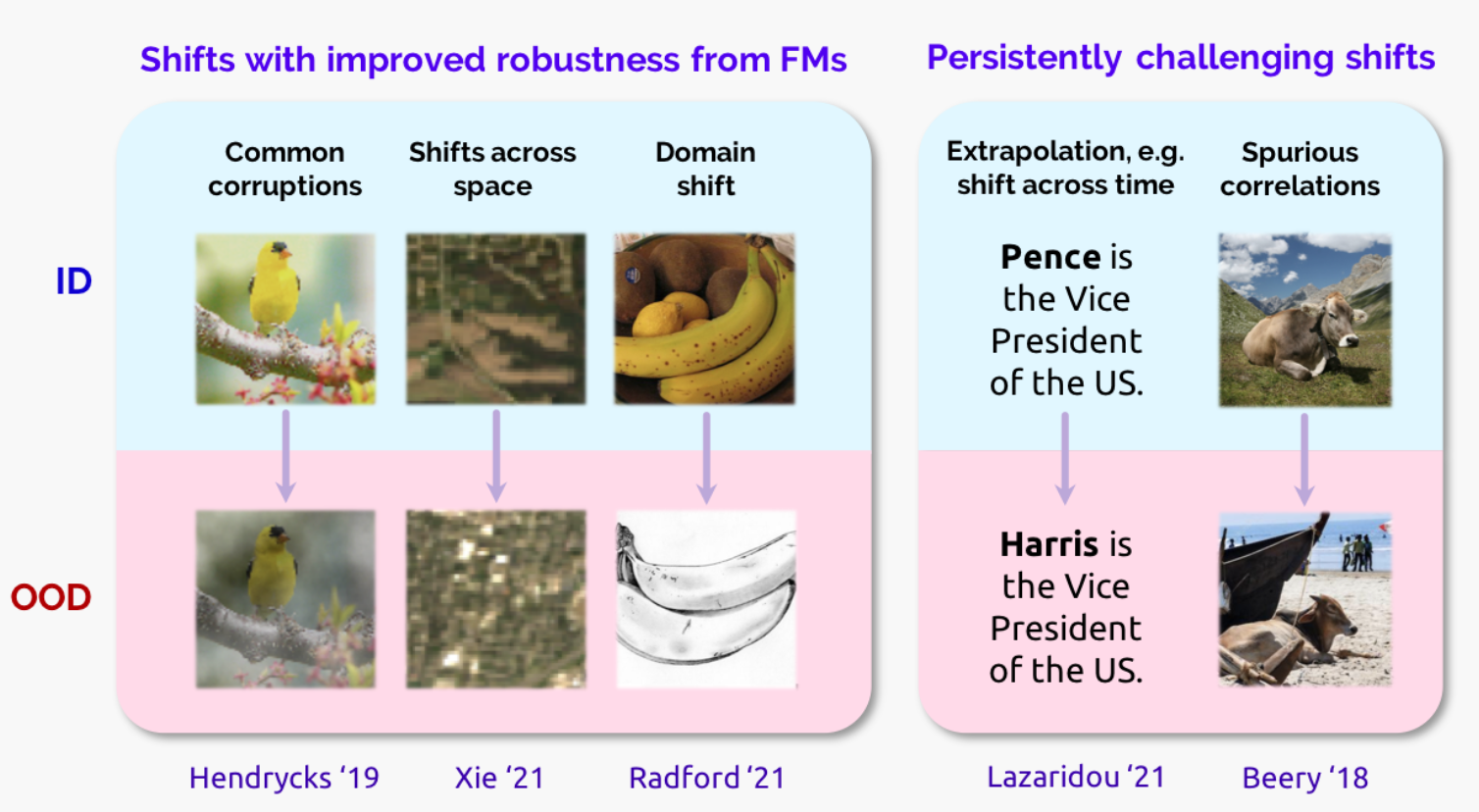
Spurious correlations
如:物体识别的背景色,标注的偏差,人口偏差,这些虚假的关联关系被模型学习到了。
Extrapolation and temporal drift
外推能力
Theory

Interpretability