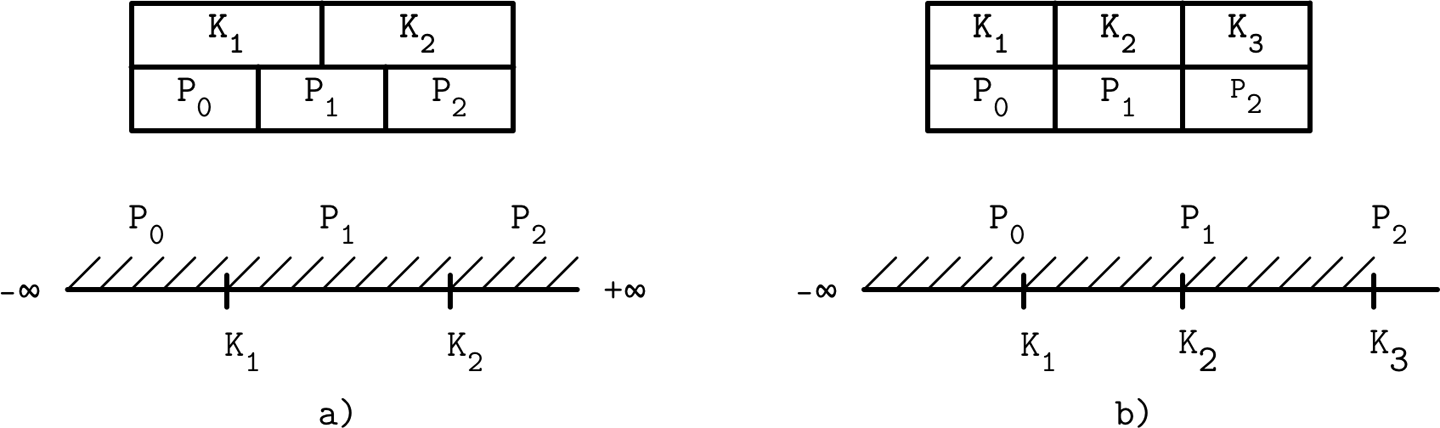
Database Basics
DBMS分类
OLTP Online Transaction Processing
面向用户的请求和事务处理,Query是预先定好的
OLAP Online Analytical Processing
复杂聚合任务,分析、存储数据,运行复杂的query
HTAP Hybrid transactional and analytical processing
混合了OLAP和OLTP的特性
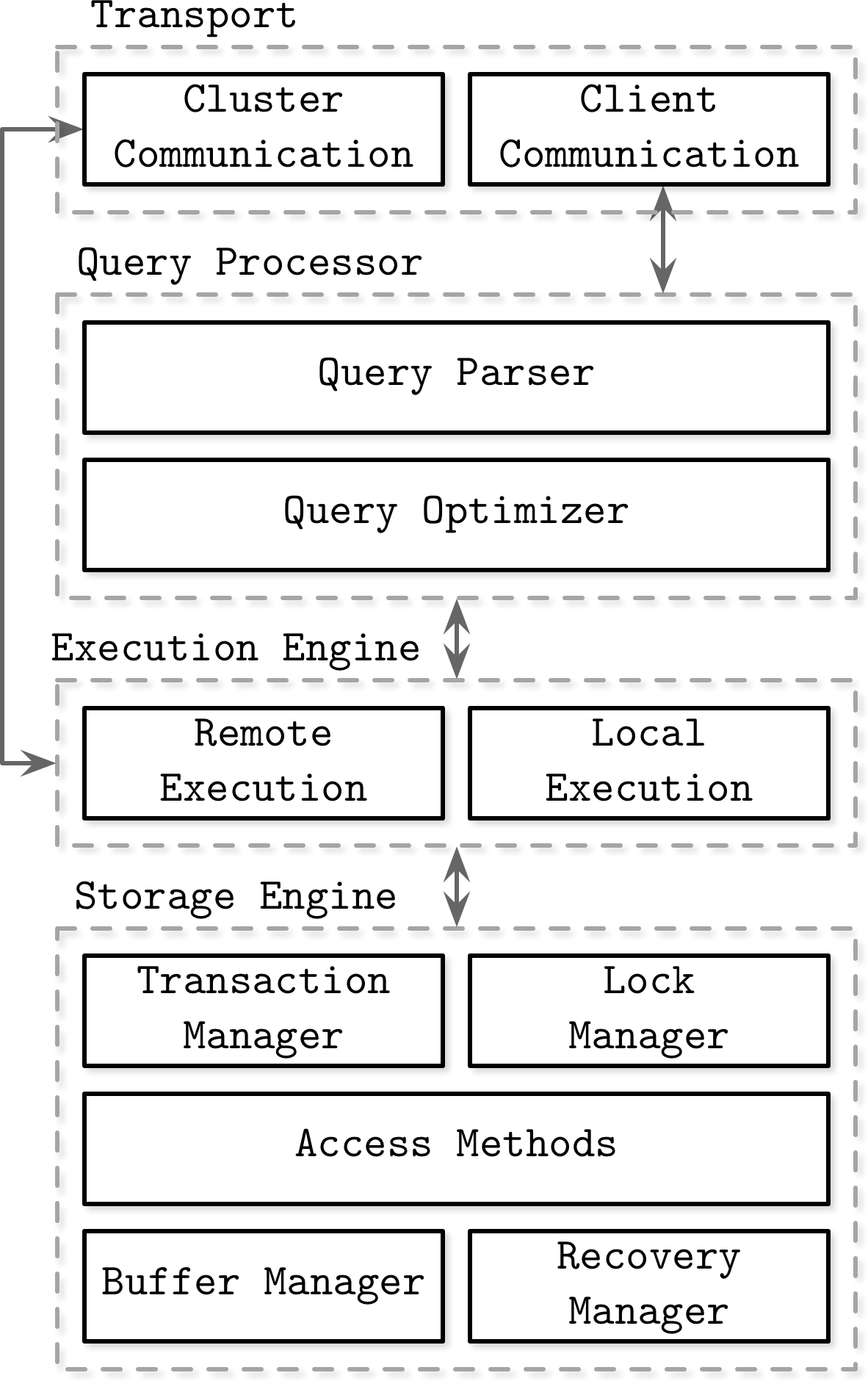
Query -> Execution plan -> Execution engine -> Storage engine
Storage Engine
Transaction Manager
管理事务,事务只有在确保一致性的情况下才能离开数据库
Lock Manager
负责给数据库对象加锁,保证数据完整性
Access Methods(storage structures)
数据在磁盘上的存取,B-Tree LSM Tree
Buffer Manager
在内存中缓存数据
Recovery Manager
存储操作日志,在出错时恢复系统状态
Memory-Based Stores
速度快,但内存价格贵,且易失
Disk-Based Database
磁盘的随机存取比内存随机存取慢得多,因此磁盘存储结构通常都是树结构,内存数据库数据结构则更加多样。
Column - vs Row- Oriented DBMS
通常数据库都存着数据记录的集合,包括行、列以及它们的交点——Field。
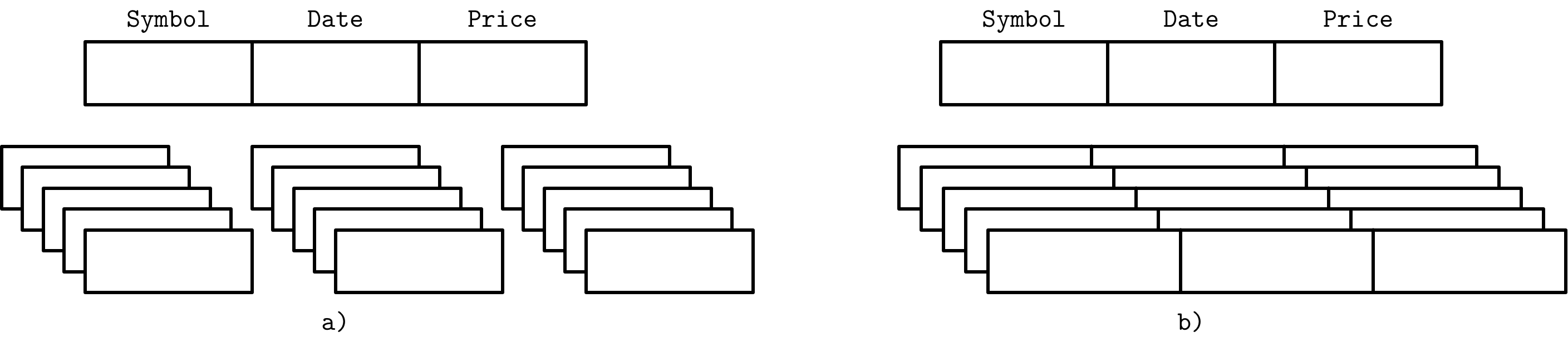
行存储的数据库很多,比如MySQL,Postgres
列存储如MonetDB C-Store,Apache Druid
在存储上,行存储在聚合查询时,会把不必要的列也拿出来,增加开销。列存储则更适合聚合,同一种数据类型存储在一起也会最大化压缩效率(对不同类型选择不同压缩算法)。
Wide Column Store
如 BigTable 和HBase
不要和Column oriented混淆了。
Wide Column Store其实是对columns进行分组,每个分组内部还是row-wise store.
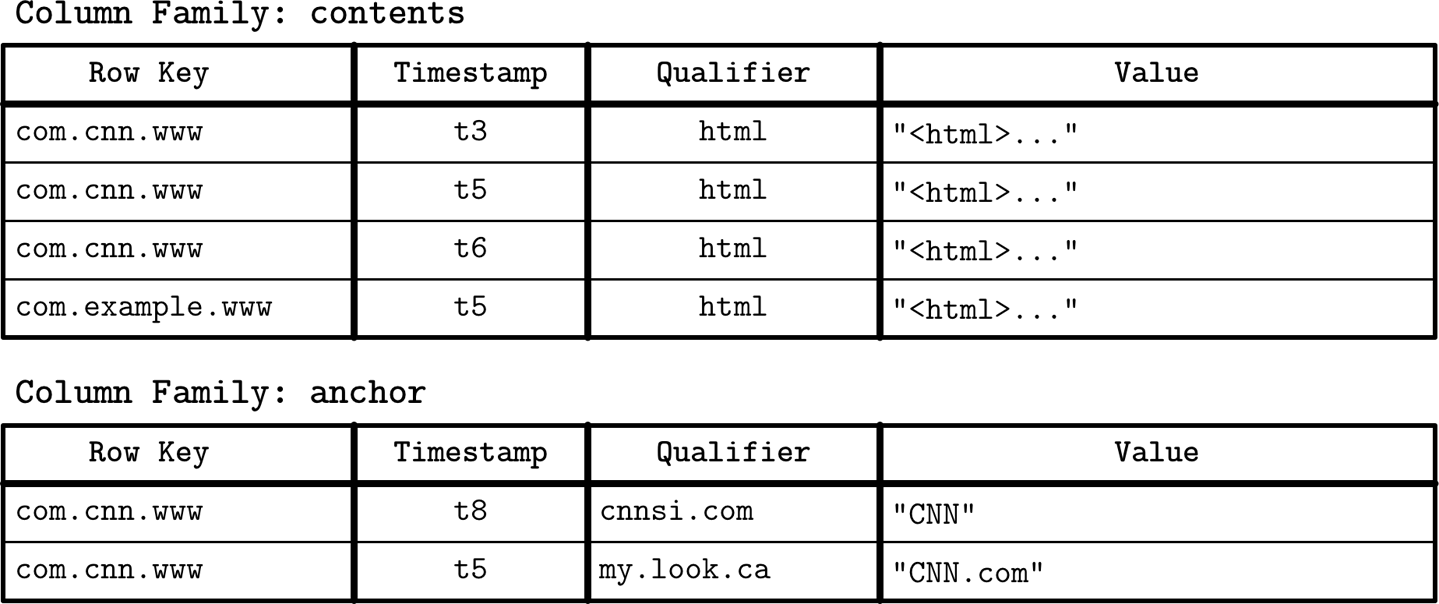
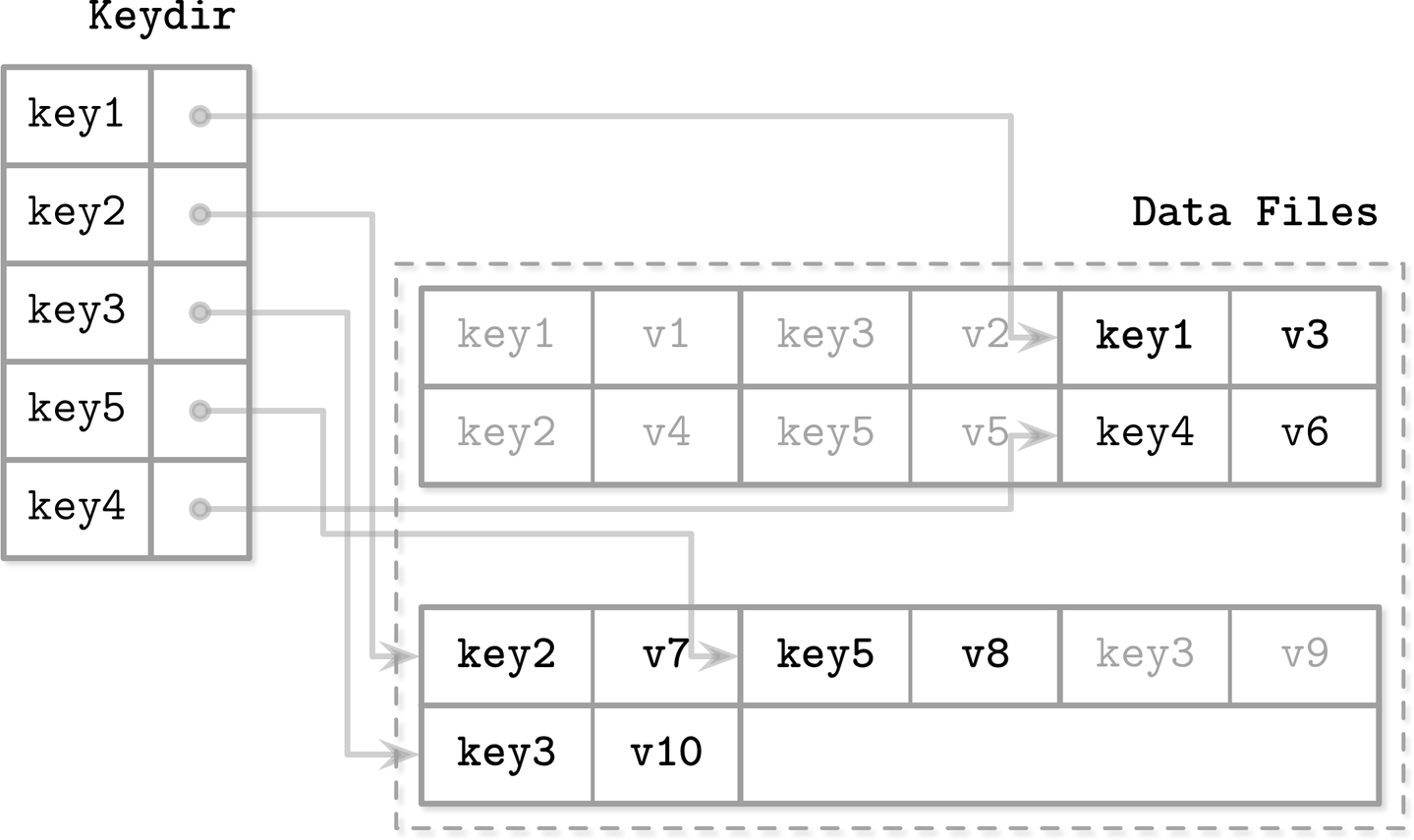
Data files and Index files
data files存储records,index files存储meta数据
Data files
多种形式,如
Index Organized Tables
Heap Organized Tables
Hash Organized Tables
Index file
在Primary data file上的index就称作Primary Index。
Secondary index可以直接指向数据record,也可以只存Primary key。
Clustered and Nonclustered:有序和无序
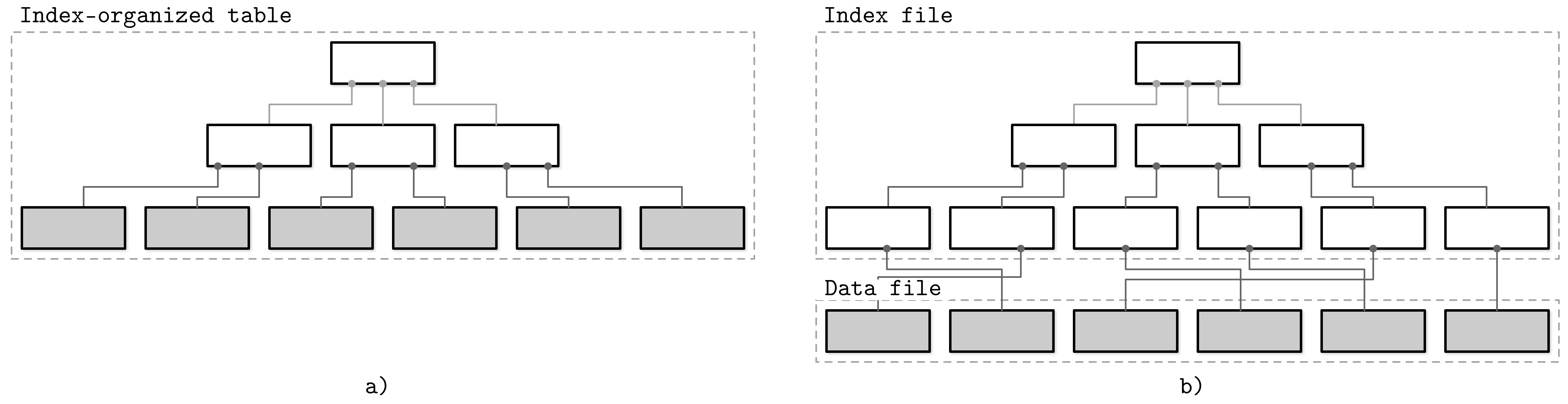
在数据表没有指定primary key时,数据库会默认创建一列主键
如果Index直接指向数据,在读取时确实减少了读盘次数,但更新时需要直接更新指针,对于Write heavy的应用来说,开销是非常大的。而Mysql InnoDB使用了两次查找的方式,Secondary Index和Primary Index。
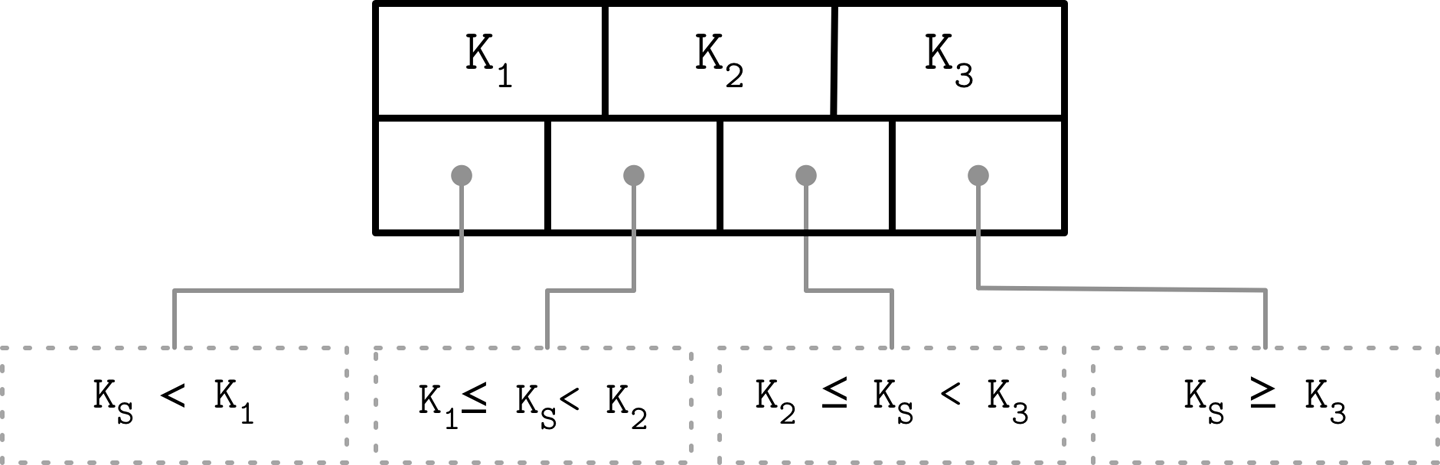
B-Tree
introduced by Rudolph Bayer and Edward M. McCreight back in 1971
Binary Search Trees(BST)
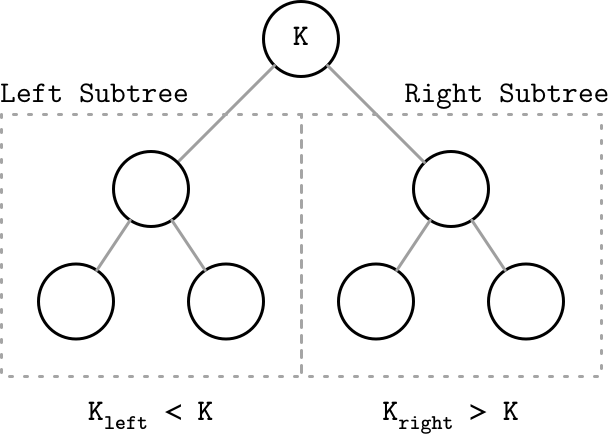
Tree Balancing
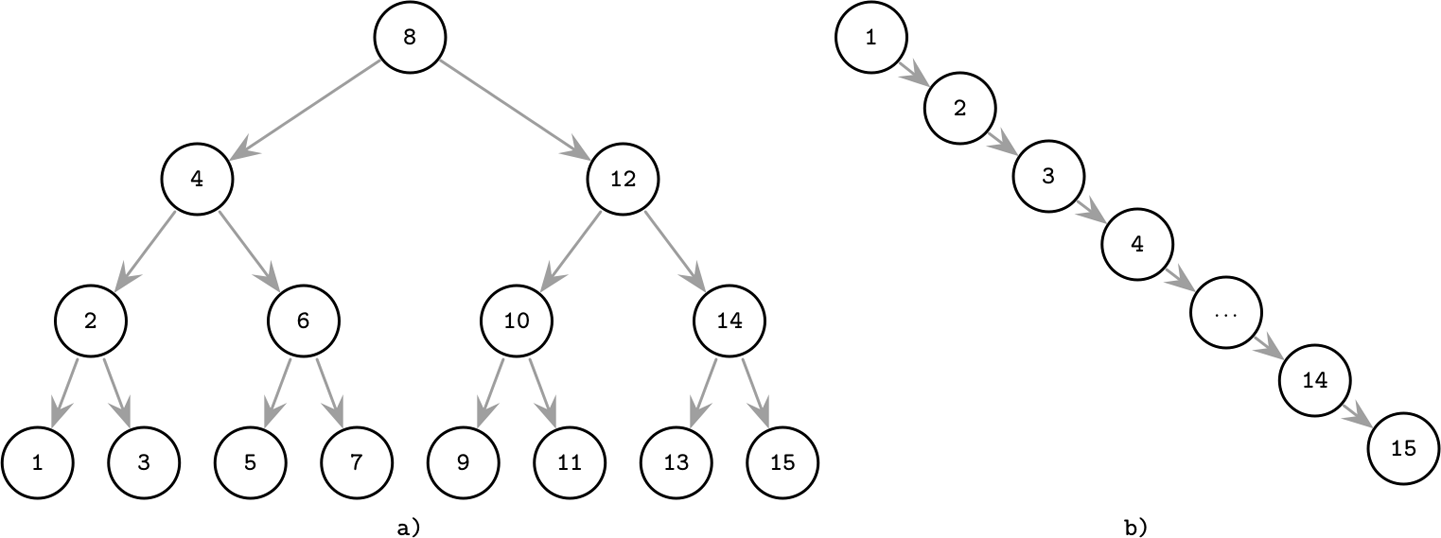
平衡 vs 不平衡 树
如果树退化了,查找复杂度就不再是Log~2~N而是N了。
二叉树旋转,中间的节点作为轴,旋转成为新的父节点
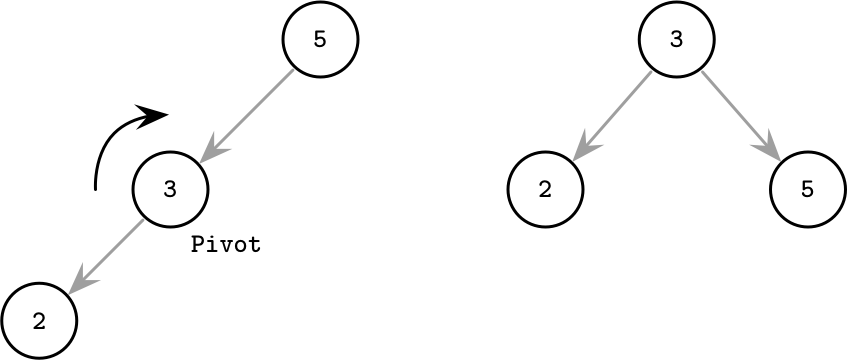
然而,BST有几个问题:
首先,每次插入都需要做平衡操作,读写开销都很大。
其次,父节点不一定存在子节点附近,如果相差很远,就需要到别的扇区读取,增加寻道时间。
所以,需要两点改进:
1、增加子节点数量,不再是2个
2、降低树的高度,减少seek次数

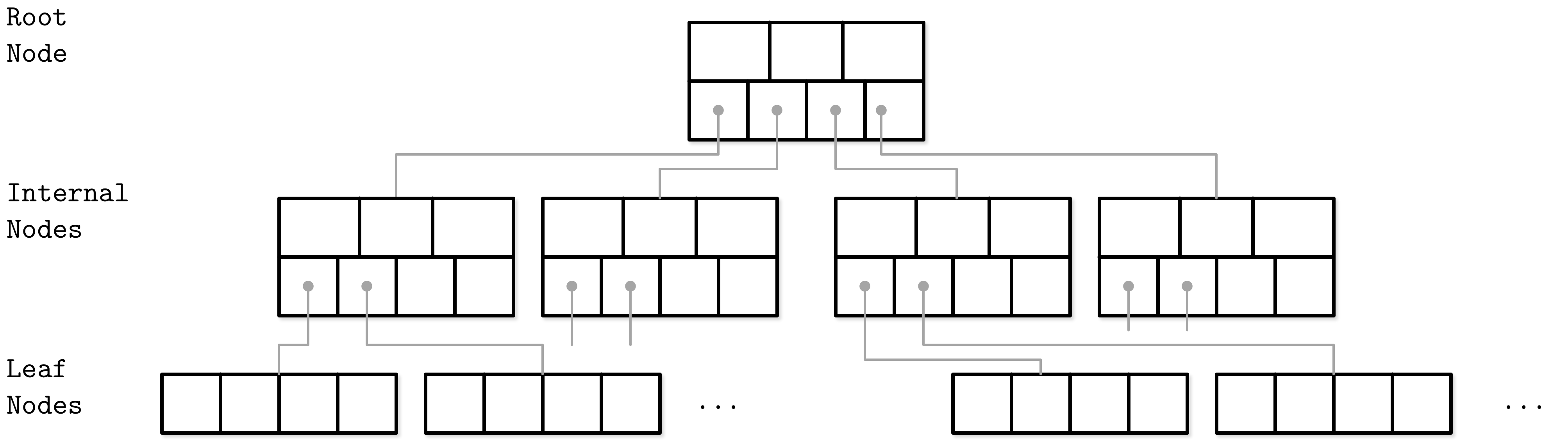
B-Tree在任何层级都可以存储数据,而B+-Tree只在叶节点存数据。
InnoDB将B+-Tree实现也称为B-Tree
B-Tree 的构建是从Bottom to top,不像BST是从Top to bottom
有些B-Tree叶节点也会包含指向兄弟节点的指针,有些是双向指针,使得最底层的叶节点也称为一个双向链表。
当节点插入的数据超过一个阈值,就会触发分裂。
当相邻节点的数据量低于N,就可以触发合并。
我们希望B-Tree也能存储在硬盘上,但是内存里的数据存储形式不是很关键,因为内存的随机存取速度很快。在硬盘上,我们就需要考虑垃圾回收,碎片整理等情况。
Big Little Endian

文件结构
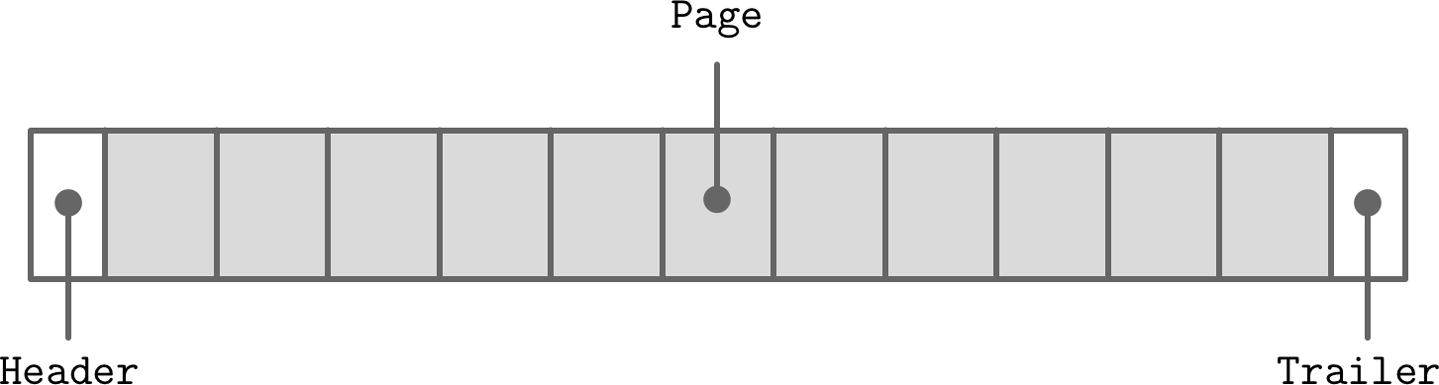
Header和Trailer都包含一些辅助信息,用于解密数据等
Simple Page Organization

有一些问题:
增加Key就涉及到移动元素
只适合固定长度的数据,不能够存取变长数据
Slotted Pages
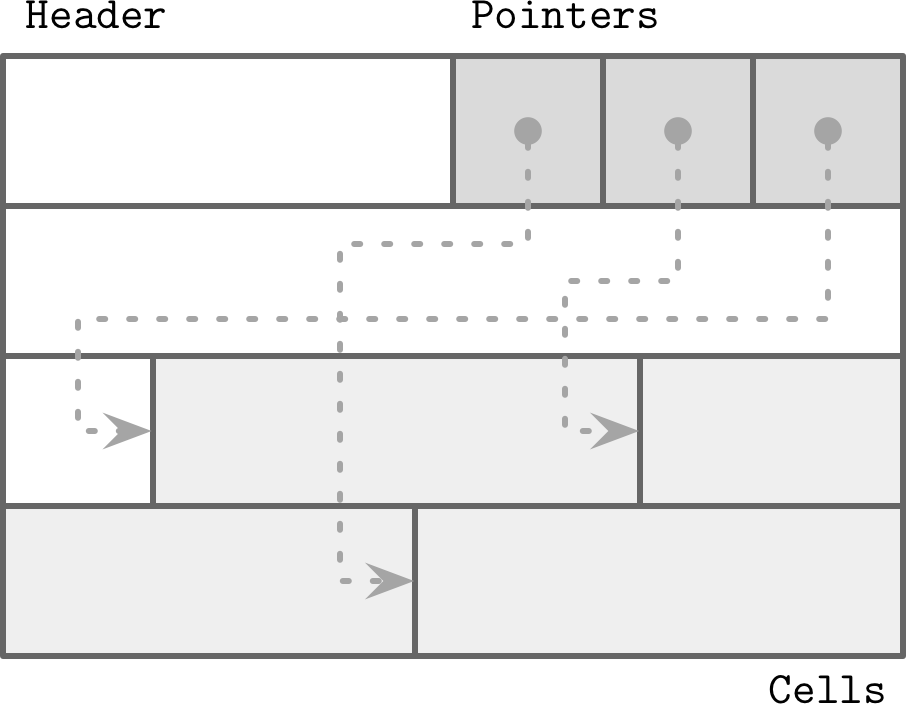
在每一个Page中,有一个Page header,包含Page和Cell的信息。然后Cell里面存储了一些数据,可以是任意数据。Pointers指向cell。
Cell的好处在于,在删除的时候只需要指针置空就好了,然后数据长度也是不固定的。碎片和不连续空间只需要重新写一遍Page就可以得到处理。
而且,如果需要排序,只需要对Pointer排序就可以,不需要对实际数据进行重新排序。
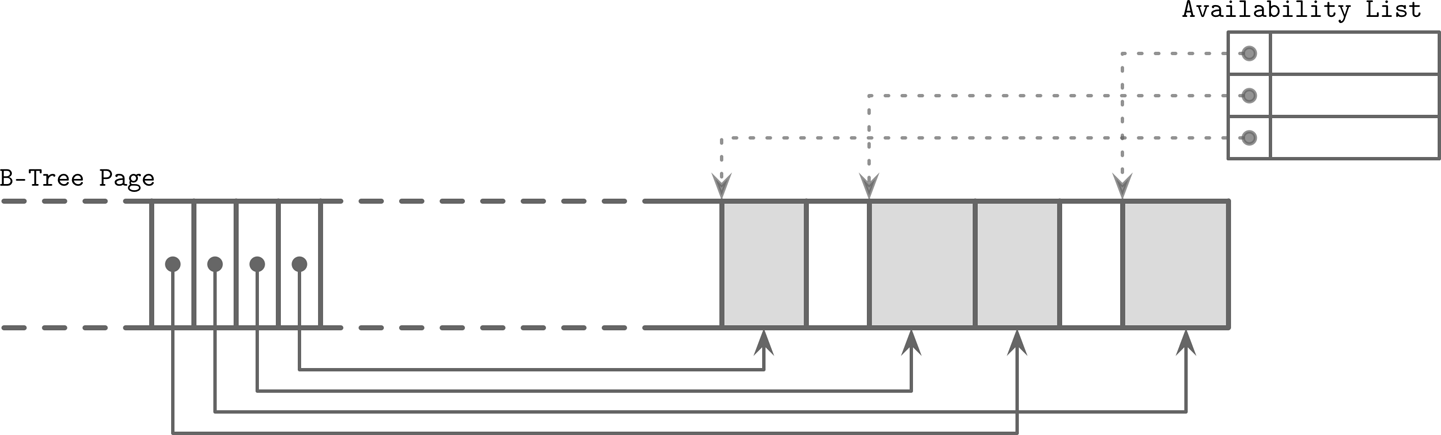
所有的空闲区域组成一个Availability List。SQLite会存储指向第一个空闲块的指针。
新的数据插入,会遵循两种:
First Fit或者Best Fit,来尝试插入。
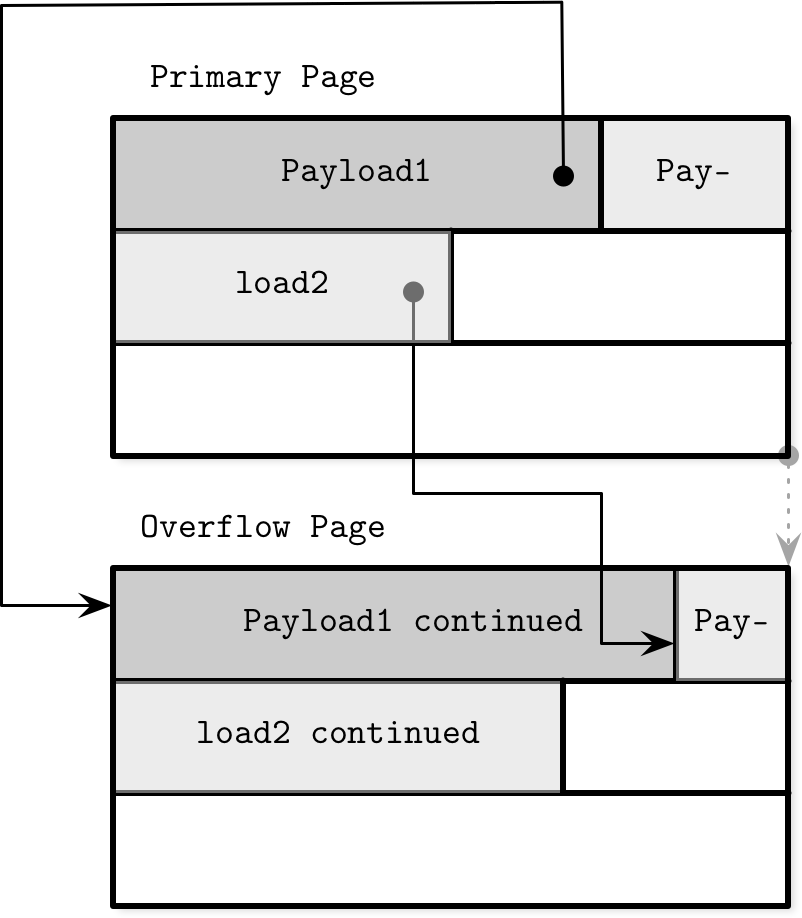
如果defragmentation之后,还是无法插入,就需要创建Overflow Page。
Page Header
Magic Numbers
代表page的id,类型或者版本。
Sibling Links
不必再去访问父节点来得到兄弟节点的信息
Rightmost Pointers
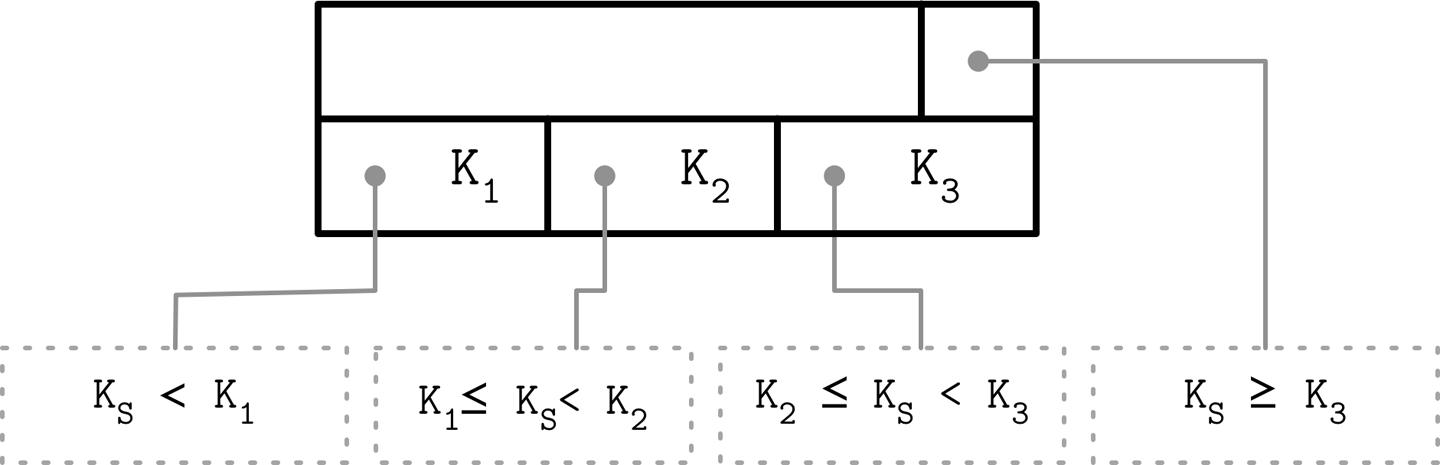
Node High Keys
指针可以成对出现,直接指向叶节点,代表叶节点的最值
Overflow Page
Breadcrumbs
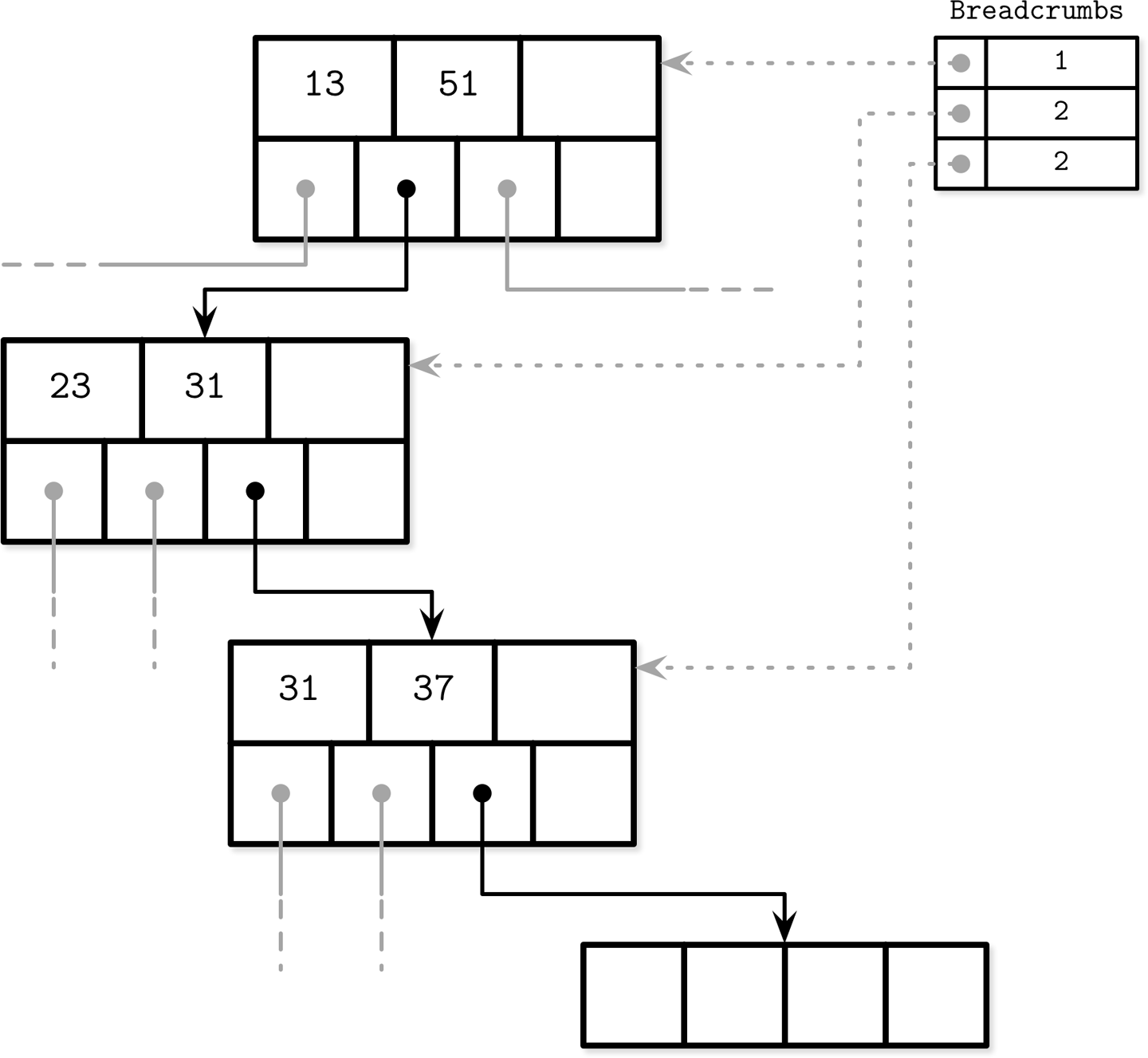
Header中存上遍历到这个节点的路径经过的节点,用于链式合并、分解节点
Right-Only Appends
如果添加的数据比最右Page的值还大,那么就可以省略查找路径的过程,直接在最右节点增加数据(Postgres)或者创建一个新的最右节点(SQLite),然后添加到父节点。
ACID
Atomicity 事务步骤是不可分割的,所有步骤成功或者都不成功。
Consistency 让数据库从一个有效状态更新到另一个有效状态,应用层
Isolation 多个并发事务应当互相不干扰。
Durability 所有更改应当能够持久化到磁盘
Cache Eviction
当Cache中的page被修改过后,它会被置脏。因此,在evict脏page时,需要先flush到磁盘,再evict。
如果每一次eviction都做flush显然开销太大,PostgreSQL有一个后台进程定时去执行任务。
Pinned Pages
由于B-Tree的特性,最上层的节点几乎总是被访问到,因此将它们持久缓存是收益很大的。
Page Replacement
FIFO LRU Clock
Clock
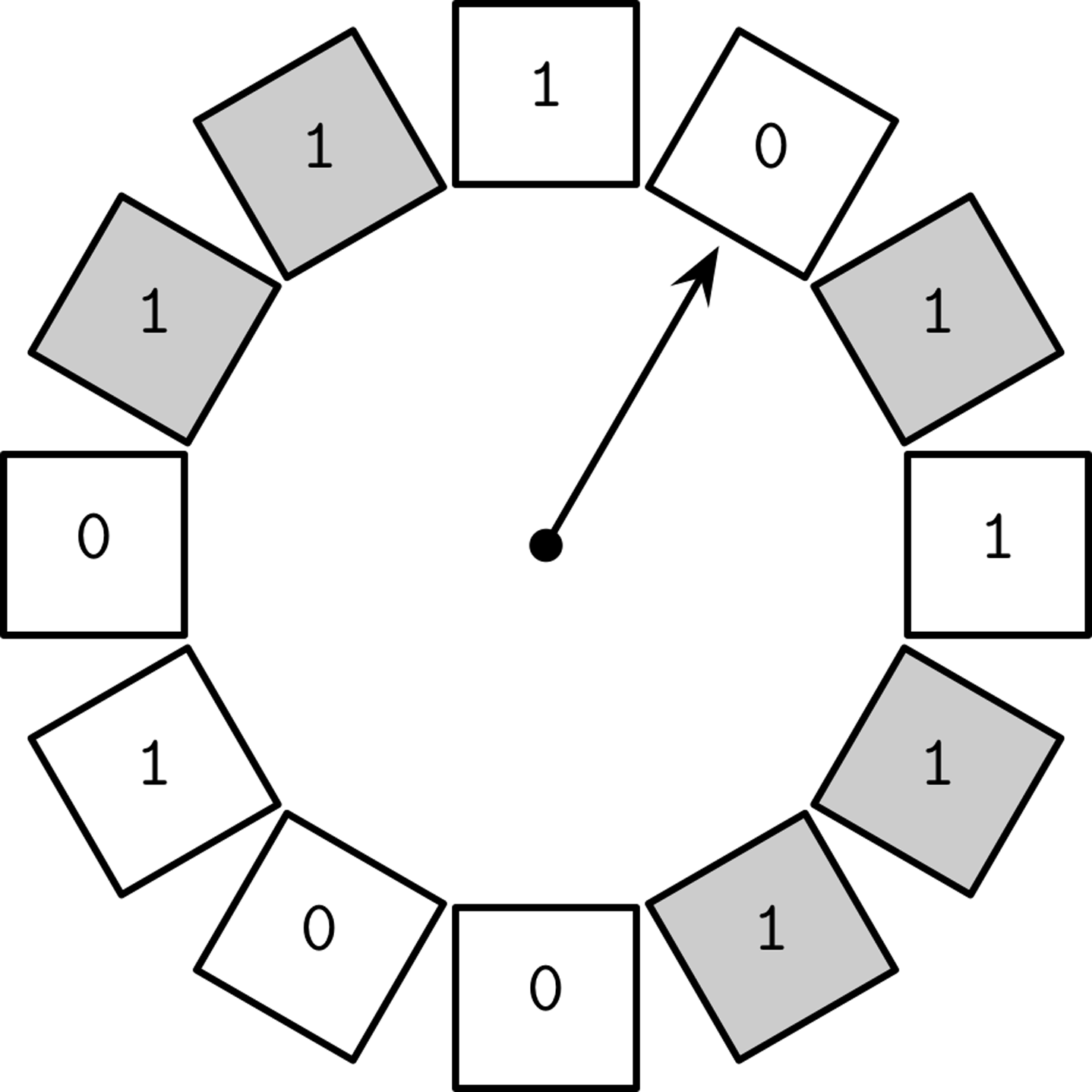
如果指针指向的Page目前没有被访问(灰色的正在被引用,白色不在被引用),将它的访问bit 置为0.如果已经是0,那么准备eviction。
LFU Least Frequently Used
Recovery
write-ahead log (commit log) 只追加,不可修改
每一条record 都有一个log sequence number(LSN)
所有数据库的写操作都要事先Log,然后才能修改Page
Page Cache能够重建
Log Checkpoint,标记到N开始的log已经被持久化,不再需要了。
Steal and force
Steal:允许还未完成事务的page flush到磁盘上。
Force: 在事务commit之前,所有修改的Page必须被flush到磁盘上
如果设置了no-steal,那么只需要redo log就可以恢复数据库
设置了force,transaction会慢的多,但重建就相对简单。
Concurrency Control
Optimistic concurrency control
如果多个事务的执行结果有分歧,其中的一个会被丢弃。所有事务都被允许并发读写,然后判断结果
Multiversion concurrency
timestamp顺序,允许多个时间点的版本共存。
Pessimistic concurrency control
lock-based: 防止其他事务修改加锁的纪录
Nonlocking: 维护一个列表,顺序执行
可能出现死锁问题
Serializable schedule
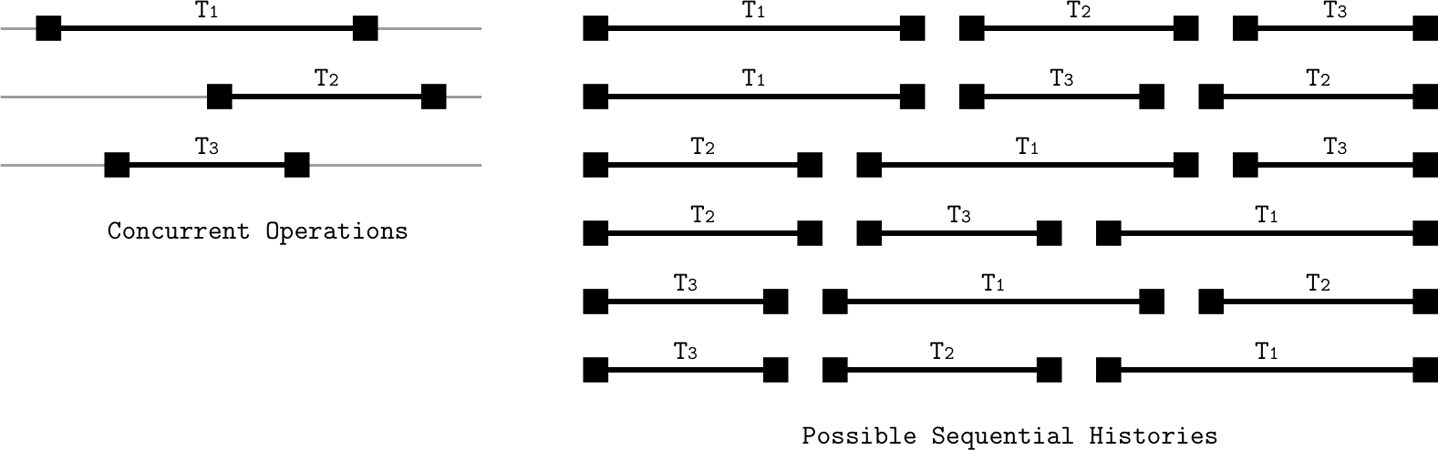
多个transaction按任意顺序执行,one by one
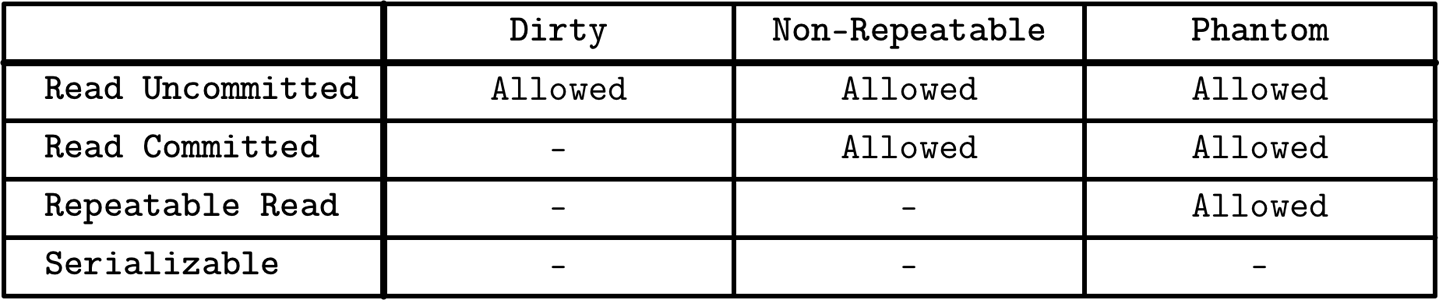
Isolation Levels
最低级别的isolation是read uncommitted,允许transaction读取dirty reads
Optimistic Concurrency Control
假设事务冲突很少,我们不需要加锁,只需要验证事务的合法性来判断是否commit。
事务被分为三步:
Read, Validation, Write
Backward-oriented 检查与已经commit的事务是否冲突
Forward-oriented 检查正在进行validation的事务是否冲突
只要有其他事务正在被validate,现在的事务就不允许commit。
Multiversion Concurrency Control
区分committed 和uncomitted的版本,对应committed和uncommitted的事务。
最后一个committed的版本就是current。
通常来说,目标就是至多有一个uncommitted值。
Pessimistic Concurrency Control
time-stamp ordering:如果时间戳更晚的事务已经提交,当前事务就只能取消
Lock-Based Concurrency Control
Two-phase locking(2PL)
Growing phase: 取得所有需要的锁
Shrinking phase:释放所有取得的锁
解决死锁:
追踪依赖图是否有环
超时、裁定优先级
Locks and Latches
Locks:逻辑数据一致性, content
Latch: 物理数据一致性, page level
RW Lock

Copy-on-write
当数据即将被修改时,创建一个备份,然后修改备份。
这样Reader读到的还是原本,不需要同步。
缺点就是占用空间较大
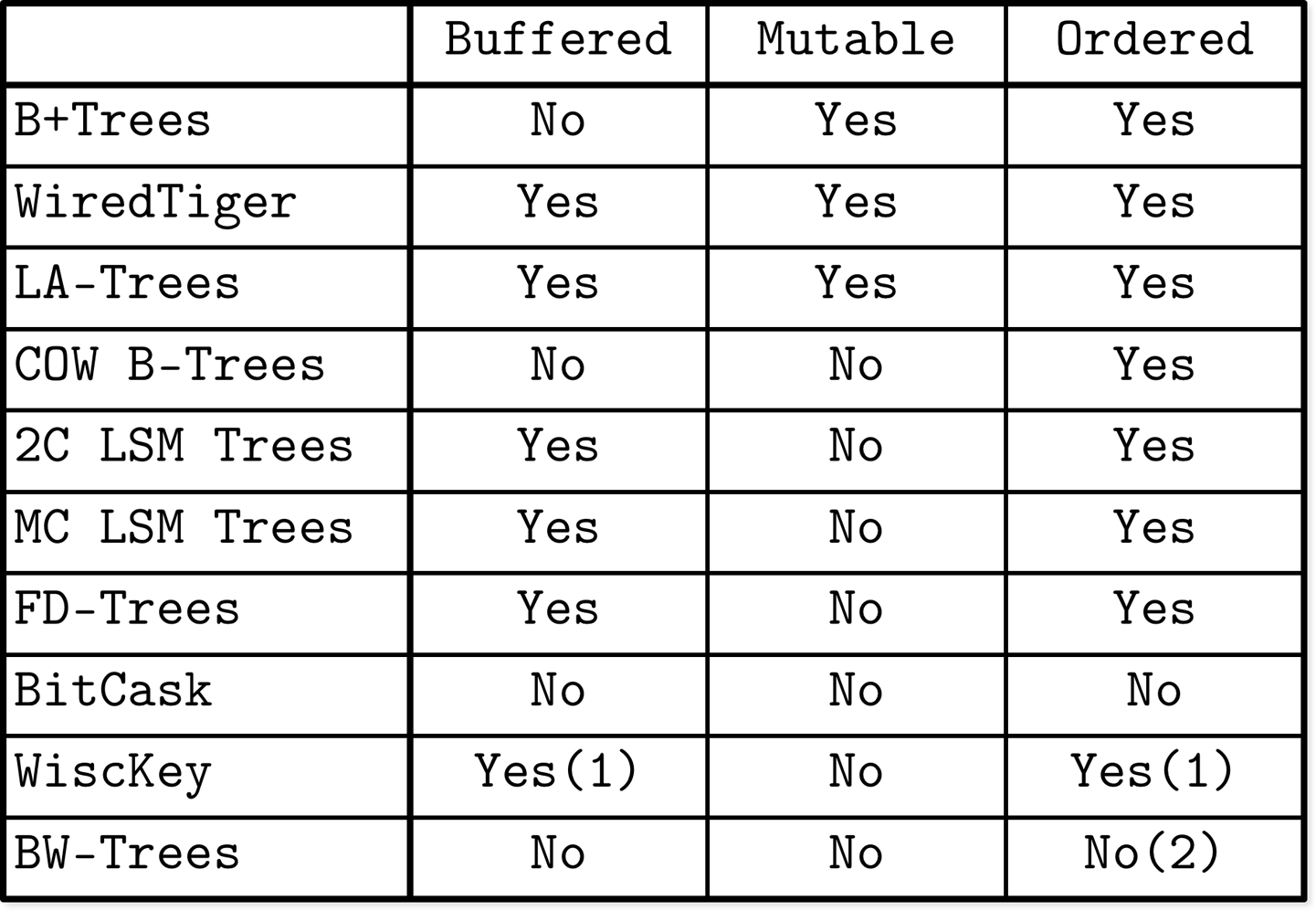
Lazy B-Tree
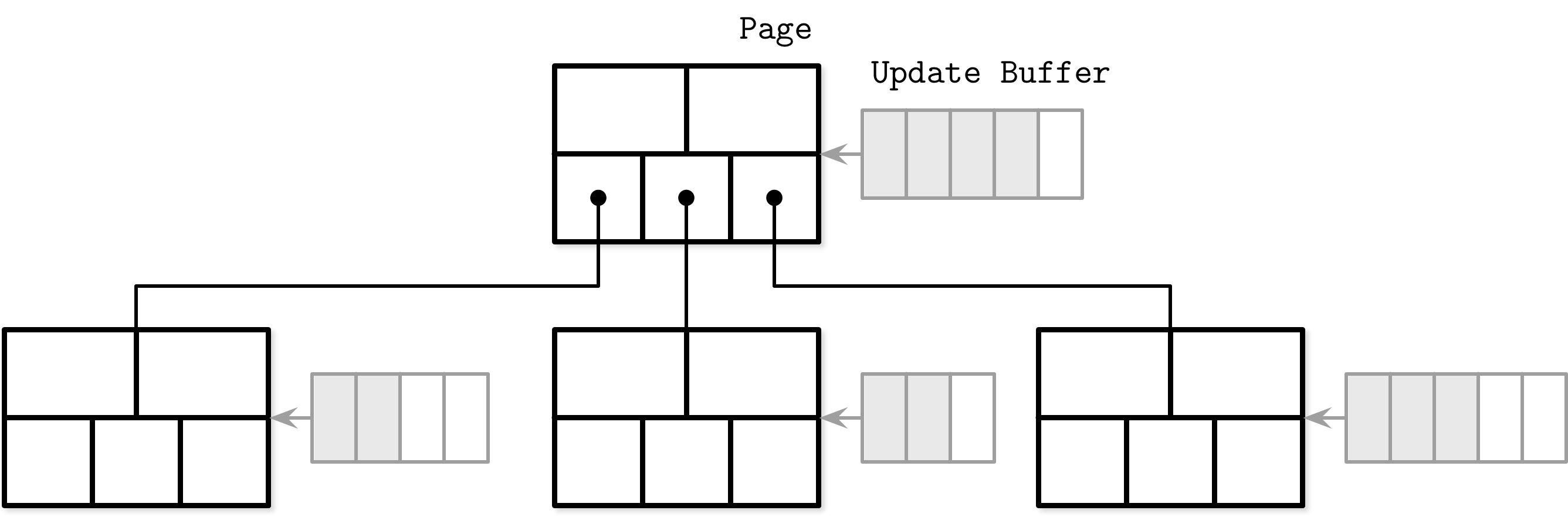
读写都会在缓存中进行,然后定期flush到树中持久化
由于split 和merge转到后台运行,r/w操作不需要等待。
Lazy Adaptive Tree
每个node都有一个buffer,当根节点buffer满了,就会写到子树的buffer,一直推到叶节点。
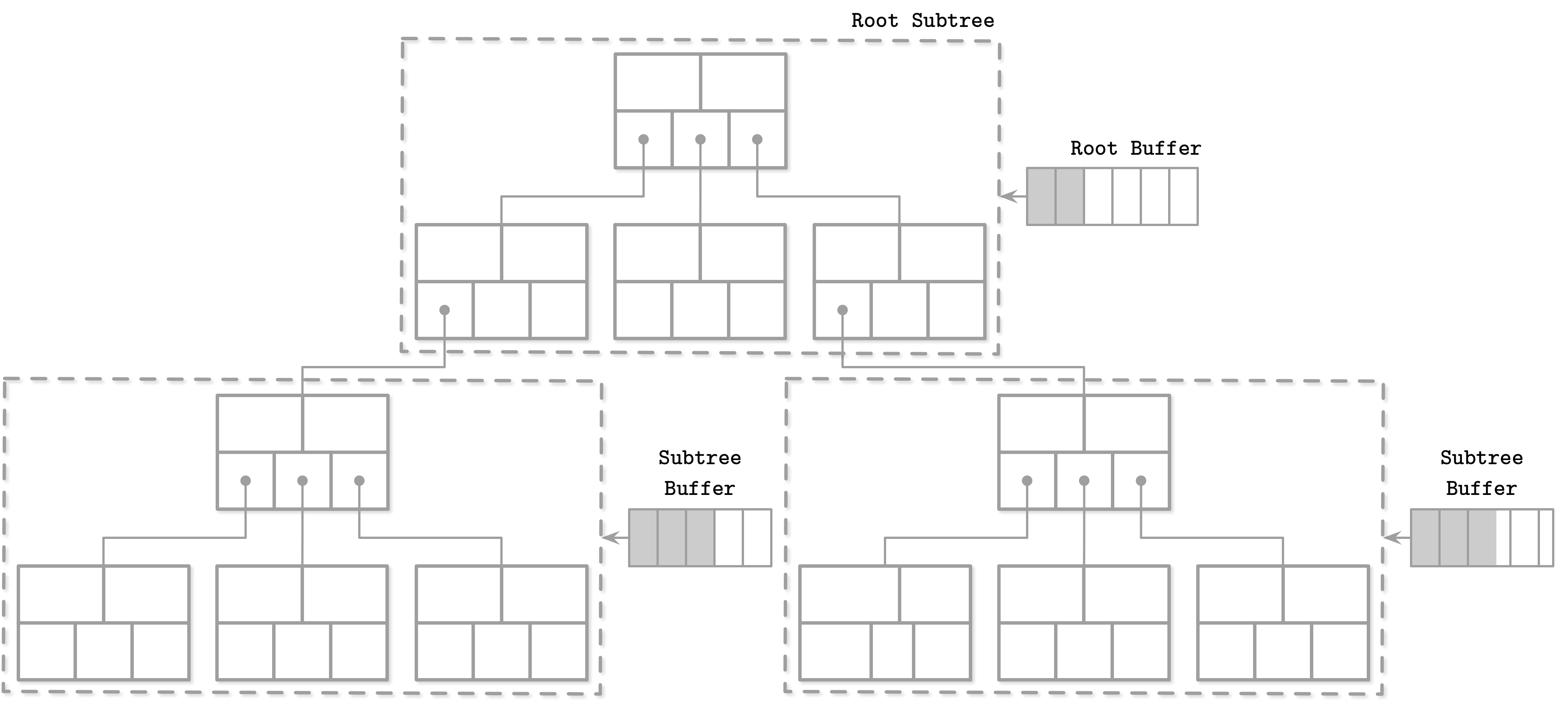
FD-Tree
假设有下列几个数组:
A1 = [12, 24, 32, 34, 39]
A2 = [22, 25, 28, 30, 35]
A3 = [11, 16, 24, 26, 30]
每个数组都向下方的数组抽元素,填充到自己的元素中
A1 = [12, 24, 25, 30, 32, 34, 39]
A2 = [16, 22, 25, 26, 28, 30, 35]
A3 = [11, 16, 24, 26, 30]
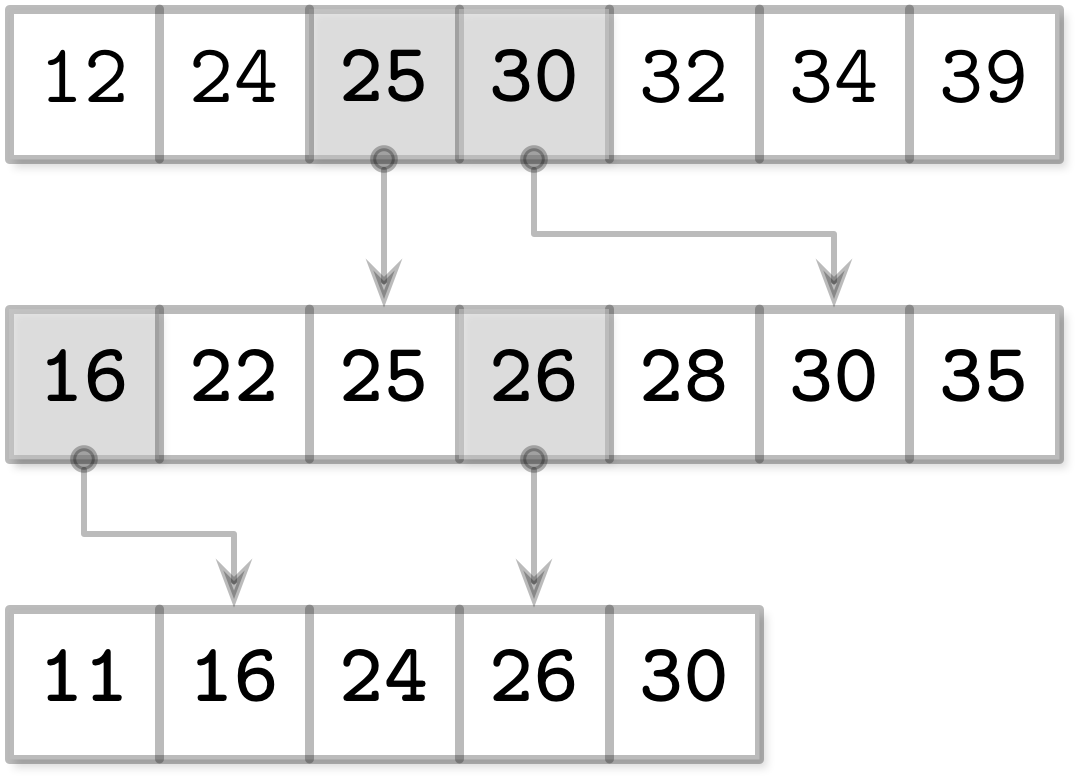
这种连接方式被称为Bridge,可以大大缩小查找空间。
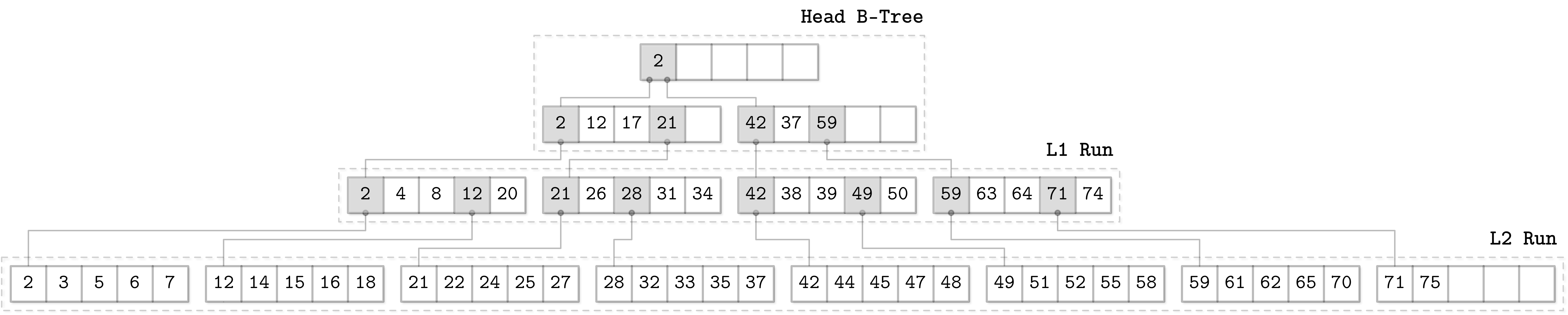
Bw-Tree
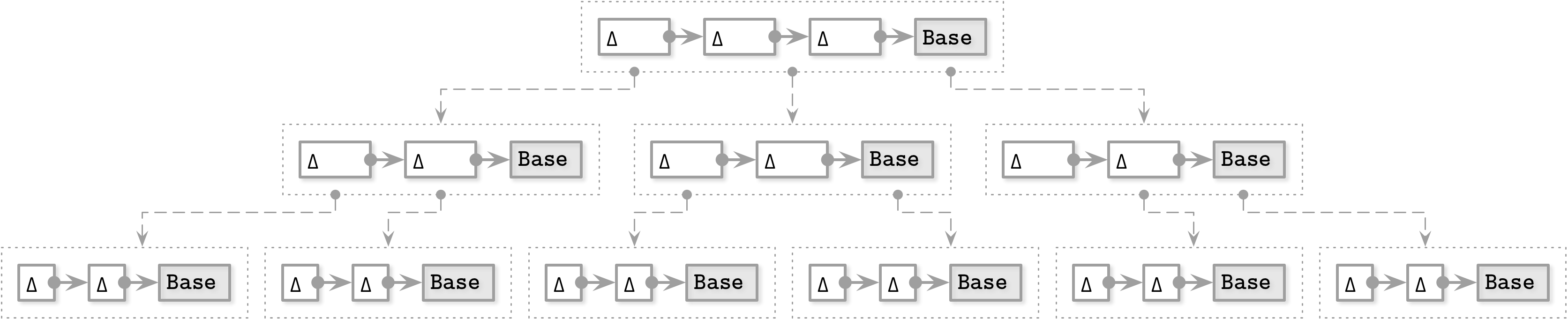
Update chain包含修改信息,Base node不做in place 修改
这样如果要更换事务顺序,只需要compare and swap,更换Update chain里的pointer就可以了。
Update chain在达到阈值后,就需要merge base node with deltas,写到新的page上然后改变父节点的指针。
LSM-Tree
Append-only
因此insert update delete不需要定位到磁盘上的record,显著提升写性能和吞吐量。
允许重复数据,冲突在读时解决
LSM Tree在写比读更多时很常用
简而言之,In-place update对读更友好,写则需要定位到位置。
Append-only对写更友好,但读取时需要取到多个版本的数据然后整合。
B-Tree也经常作为LSM Tree的索引结构
LSM树将数据的写缓存到内存里的表结构中。读和写分离,所以读写可以同时进行。
当LSM树接收到写请求后,存到mutable memtable中,buffer and sort。达到一定阈值后,持久化到磁盘。
Two and Multi component LSM Trees
Two component只有一个磁盘树。对每个内存中的子树,都和磁盘中对应的子树合并,生成一个新的子树写到新的磁盘区域。当子树被flush之后,之前的树就被丢弃了,取而代之的是新的树。
【Paper笔记】The Log structured Merge-Tree(LSM-Tree) · (kernelmaker.github.io)
Multicomponent
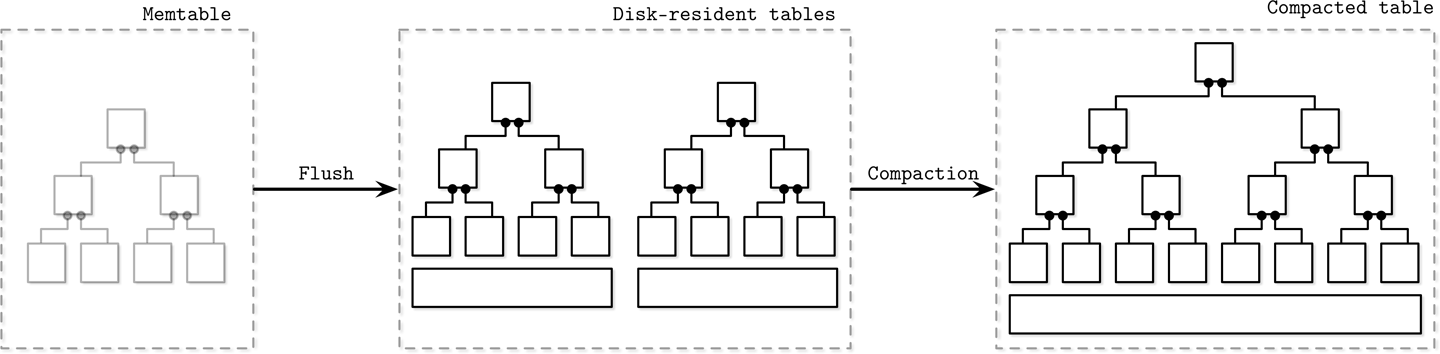
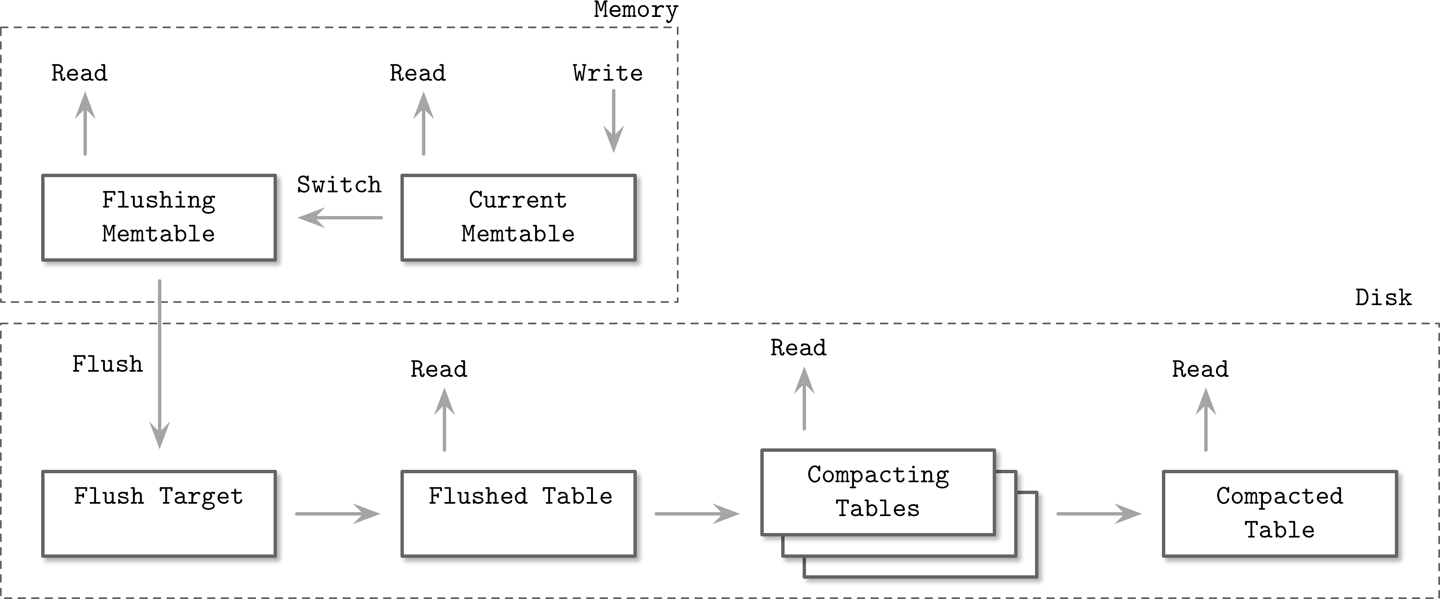
在LSM中,Update和Insert是无法区分的,因此可以称作Upsert
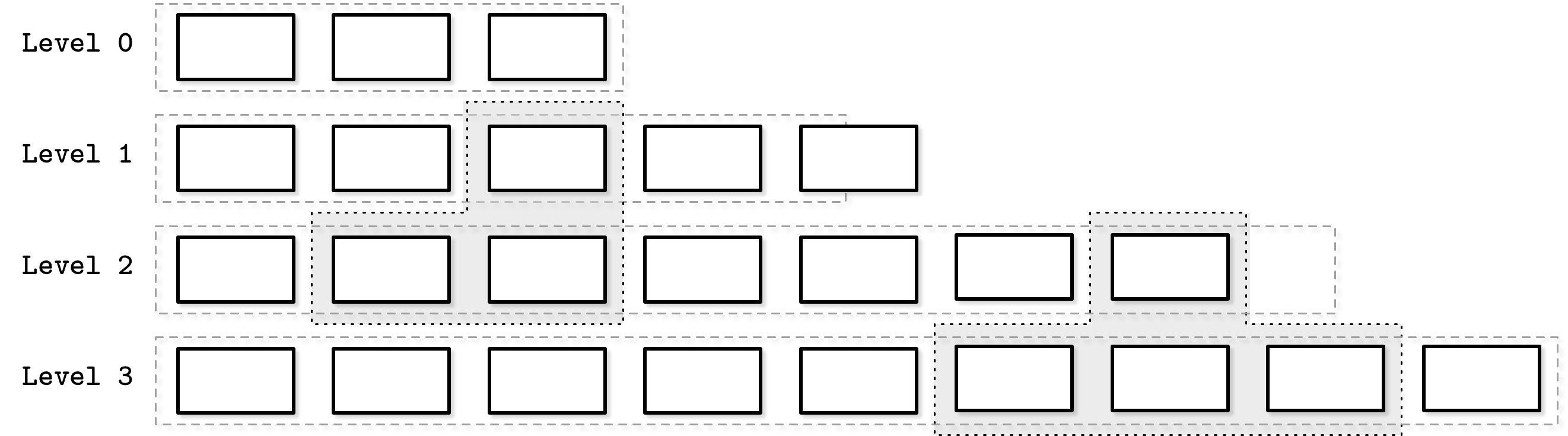
Compaction
根据树的层级进行整合
LSM的disk-resident table是SSTable( Sorted String Table),一般包含一个index file和 data file,index file可以使用B-Tree或哈希表。
Bloom Filter
使用一个大型的bit array,多个哈希函数。
对每个record的键进行哈希操作,把得到结果作为下标的位置为1。
如果给定一个key,所有哈希函数对它求哈希值后对应的位都是1,那么它很有可能在这个集合中,否则只要有1个出现0,那么它一定不在集合中。
Skiplist

每个节点的高度都是随机的。
假如从10出发,找7。
1、10>7,回退到下一层的上一个节点
2、到达5,5<7,前进,又回到10,还是比7大,回退下一层的上一个节点
3、到达7
Keydir